无插件Vim编程技巧
 相信大家看过《简明Vim教程》也玩了《Vim大冒险》的游戏了,相信大家对Vim都有一个好的入门了。我在这里把我日常用Vim编程的一些技巧列出来给大家看看,希望对大家有用,另外,也是一个抛砖引玉的过程,也希望大家把你们的技巧跟贴一下,我会更新到这篇文章中。另外,这篇文章里的这些技巧全都是vim原生态的,不需要你安装什么插件。我的Vim的版本是7.2。
相信大家看过《简明Vim教程》也玩了《Vim大冒险》的游戏了,相信大家对Vim都有一个好的入门了。我在这里把我日常用Vim编程的一些技巧列出来给大家看看,希望对大家有用,另外,也是一个抛砖引玉的过程,也希望大家把你们的技巧跟贴一下,我会更新到这篇文章中。另外,这篇文章里的这些技巧全都是vim原生态的,不需要你安装什么插件。我的Vim的版本是7.2。
浏览代码
首先,我们先从浏览代码开始。有时候,我们需要看多个文件,所以,传统的做法是,我们开多个tty终端,每个tty里用Vim打开一个文件,然后来回切换。这很没有什么效率。我们希望在一个Vim里打开多个文件,甚至浏览程序目录。
浏览目录的命令很简单:(你也可以直接vim一个目录)
:E
注意,是大写。于是,你会看到下面这样的界面:

 (45 人打了分,平均分: 4.22 )
(45 人打了分,平均分: 4.22 ) Python的修饰器的英文名叫Decorator,当你看到这个英文名的时候,你可能会把其跟Design Pattern里的Decorator搞混了,其实这是完全不同的两个东西。虽然好像,他们要干的事都很相似——都是想要对一个已有的模块做一些“修饰工作”,所谓修饰工作就是想给现有的模块加上一些小装饰(一些小功能,这些小功能可能好多模块都会用到),但又不让这个小装饰(小功能)侵入到原有的模块中的代码里去。但是OO的Decorator简直就是一场恶梦,不信你就去看看wikipedia上的词条(
Python的修饰器的英文名叫Decorator,当你看到这个英文名的时候,你可能会把其跟Design Pattern里的Decorator搞混了,其实这是完全不同的两个东西。虽然好像,他们要干的事都很相似——都是想要对一个已有的模块做一些“修饰工作”,所谓修饰工作就是想给现有的模块加上一些小装饰(一些小功能,这些小功能可能好多模块都会用到),但又不让这个小装饰(小功能)侵入到原有的模块中的代码里去。但是OO的Decorator简直就是一场恶梦,不信你就去看看wikipedia上的词条( 酷壳似乎好长时间没有像《
酷壳似乎好长时间没有像《
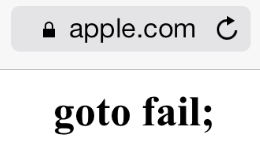 2014年2月22日,在这个“这么二”的日子里,苹果公司推送了 iOS 7.0.6(版本号11B651)修复了 SSL 连接验证的一个 bug。官方网页在这里:
2014年2月22日,在这个“这么二”的日子里,苹果公司推送了 iOS 7.0.6(版本号11B651)修复了 SSL 连接验证的一个 bug。官方网页在这里:
 Egor Homakov(Twitter:
Egor Homakov(Twitter:  当我们在生产线上用一台服务器来提供数据服务的时候,我会遇到如下的两个问题:
当我们在生产线上用一台服务器来提供数据服务的时候,我会遇到如下的两个问题: 当我们说起函数式编程来说,我们会看到如下函数式编程的长相:
当我们说起函数式编程来说,我们会看到如下函数式编程的长相: X-Y Problem
X-Y Problem 这几天系统地学习了一下
这几天系统地学习了一下