7个示例科普CPU Cache
(感谢网友 @我的上铺叫路遥 翻译投稿)
CPU cache一直是理解计算机体系架构的重要知识点,也是并发编程设计中的技术难点,而且相关参考资料如同过江之鲫,浩瀚繁星,阅之如临深渊,味同嚼蜡,三言两语难以入门。正好网上有人推荐了微软大牛Igor Ostrovsky一篇博文《漫游处理器缓存效应》,文章不仅仅用7个最简单的源码示例就将CPU cache的原理娓娓道来,还附加图表量化分析做数学上的佐证,个人感觉这种案例教学的切入方式绝对是俺的菜,故而忍不住贸然译之,以飨列位看官。
原文地址:Gallery of Processor Cache Effects
大多数读者都知道cache是一种快速小型的内存,用以存储最近访问内存位置。这种描述合理而准确,但是更多地了解一些处理器缓存工作中的“烦人”细节对于理解程序运行性能有很大帮助。
在这篇博客中,我将运用代码示例来详解cache工作的方方面面,以及对现实世界中程序运行产生的影响。
下面的例子都是用C#写的,但语言的选择同程序运行状况以及得出的结论几乎没什么影响。
目录
示例1:内存访问和运行
你认为相较于循环1,循环2会运行多快?
int[] arr = new int[64 * 1024 * 1024]; // Loop 1 for (int i = 0; i < arr.Length; i++) arr[i] *= 3; // Loop 2 for (int i = 0; i < arr.Length; i += 16) arr[i] *= 3;
第一个循环将数组的每个值乘3,第二个循环将每16个值乘3,第二个循环只做了第一个约6%的工作,但在现代机器上,两者几乎运行相同时间:在我机器上分别是80毫秒和78毫秒。
两个循环花费相同时间的原因跟内存有关。循环执行时间长短由数组的内存访问次数决定的,而非整型数的乘法运算次数。经过下面对第二个示例的解释,你会发现硬件对这两个循环的主存访问次数是相同的。
示例2:缓存行的影响
让我们进一步探索这个例子。我们将尝试不同的循环步长,而不仅仅是1和16。
for (int i = 0; i < arr.Length; i += K) arr[i] *= 3;
下图为该循环在不同步长(K)下的运行时间:
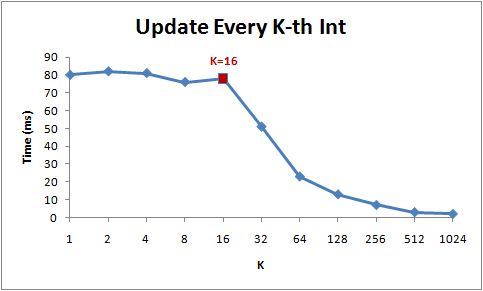
注意当步长在1到16范围内,循环运行时间几乎不变。但从16开始,每次步长加倍,运行时间减半。
背后的原因是今天的CPU不再是按字节访问内存,而是以64字节为单位的块(chunk)拿取,称为一个缓存行(cache line)。当你读一个特定的内存地址,整个缓存行将从主存换入缓存,并且访问同一个缓存行内的其它值的开销是很小的。
由于16个整型数占用64字节(一个缓存行),for循环步长在1到16之间必定接触到相同数目的缓存行:即数组中所有的缓存行。当步长为32,我们只有大约每两个缓存行接触一次,当步长为64,只有每四个接触一次。
理解缓存行对某些类型的程序优化而言可能很重要。比如,数据字节对齐可能决定一次操作接触1个还是2个缓存行。那上面的例子来说,很显然操作不对齐的数据将损失一半性能。
示例3:L1和L2缓存大小
今天的计算机具有两级或三级缓存,通常叫做L1、L2以及可能的L3(译者注:如果你不明白什么叫二级缓存,可以参考这篇精悍的博文lol)。如果你想知道不同缓存的大小,你可以使用系统内部工具CoreInfo,或者Windows API调用GetLogicalProcessorInfo。两者都将告诉你缓存行以及缓存本身的大小。
在我的机器上,CoreInfo现实我有一个32KB的L1数据缓存,一个32KB的L1指令缓存,还有一个4MB大小L2数据缓存。L1缓存是处理器独享的,L2缓存是成对处理器共享的。
Logical Processor to Cache Map:
*— Data Cache 0, Level 1, 32 KB, Assoc 8, LineSize 64
*— Instruction Cache 0, Level 1, 32 KB, Assoc 8, LineSize 64
-*– Data Cache 1, Level 1, 32 KB, Assoc 8, LineSize 64
-*– Instruction Cache 1, Level 1, 32 KB, Assoc 8, LineSize 64
**– Unified Cache 0, Level 2, 4 MB, Assoc 16, LineSize 64
–*- Data Cache 2, Level 1, 32 KB, Assoc 8, LineSize 64
–*- Instruction Cache 2, Level 1, 32 KB, Assoc 8, LineSize 64
—* Data Cache 3, Level 1, 32 KB, Assoc 8, LineSize 64
—* Instruction Cache 3, Level 1, 32 KB, Assoc 8, LineSize 64
–** Unified Cache 1, Level 2, 4 MB, Assoc 16, LineSize 64
(译者注:作者平台是四核机,所以L1编号为0~3,数据/指令各一个,L2只有数据缓存,两个处理器共享一个,编号0~1。关联性字段在后面例子说明。)
让我们通过一个实验来验证这些数字。遍历一个整型数组,每16个值自增1——一种节约地方式改变每个缓存行。当遍历到最后一个值,就重头开始。我们将使用不同的数组大小,可以看到当数组溢出一级缓存大小,程序运行的性能将急剧滑落。
int steps = 64 * 1024 * 1024;
// Arbitrary number of steps
int lengthMod = arr.Length - 1;
for (int i = 0; i < steps; i++)
{
arr[(i * 16) & lengthMod]++; // (x & lengthMod) is equal to (x % arr.Length)
}
下图是运行时间图表:
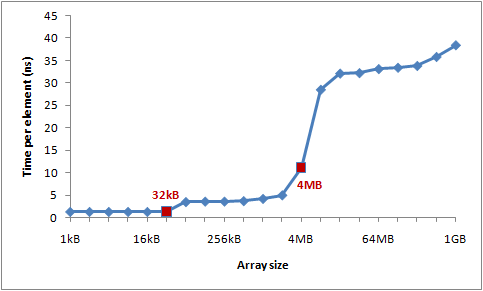
你可以看到在32KB和4MB之后性能明显滑落——正好是我机器上L1和L2缓存大小。