K-Means 算法
最近在学习一些数据挖掘的算法,看到了这个算法,也许这个算法对你来说很简单,但对我来说,我是一个初学者,我在网上翻看了很多资料,发现中文社区没有把这个问题讲得很全面很清楚的文章,所以,把我的学习笔记记录下来,分享给大家。
在数据挖掘中, k-Means 算法是一种 cluster analysis 的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法。
目录
问题
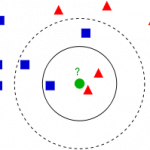
K-Means算法主要解决的问题如下图所示。我们可以看到,在图的左边有一些点,我们用肉眼可以看出来有四个点群,但是我们怎么通过计算机程序找出这几个点群来呢?于是就出现了我们的K-Means算法(Wikipedia链接)

算法概要
这个算法其实很简单,如下图所示:

从上图中,我们可以看到,A, B, C, D, E 是五个在图中点。而灰色的点是我们的种子点,也就是我们用来找点群的点。有两个种子点,所以K=2。
然后,K-Means的算法如下:
- 随机在图中取K(这里K=2)个种子点。
- 然后对图中的所有点求到这K个种子点的距离,假如点Pi离种子点Si最近,那么Pi属于Si点群。(上图中,我们可以看到A,B属于上面的种子点,C,D,E属于下面中部的种子点)
- 接下来,我们要移动种子点到属于他的“点群”的中心。(见图上的第三步)
- 然后重复第2)和第3)步,直到,种子点没有移动(我们可以看到图中的第四步上面的种子点聚合了A,B,C,下面的种子点聚合了D,E)。
这个算法很简单,但是有些细节我要提一下,求距离的公式我不说了,大家有初中毕业水平的人都应该知道怎么算的。我重点想说一下“求点群中心的算法”
求点群中心的算法
一般来说,求点群中心点的算法你可以很简的使用各个点的X/Y坐标的平均值。不过,我这里想告诉大家另三个求中心点的的公式:
1)Minkowski Distance 公式 —— λ 可以随意取值,可以是负数,也可以是正数,或是无穷大。

2)Euclidean Distance 公式 —— 也就是第一个公式 λ=2 的情况

3)CityBlock Distance 公式 —— 也就是第一个公式 λ=1 的情况
![]()
这三个公式的求中心点有一些不一样的地方,我们看下图(对于第一个 λ 在 0-1之间)。



(1)Minkowski Distance (2)Euclidean Distance (3) CityBlock Distance
上面这几个图的大意是他们是怎么个逼近中心的,第一个图以星形的方式,第二个图以同心圆的方式,第三个图以菱形的方式。
K-Means的演示
如果你以”K Means Demo“为关键字到Google里查你可以查到很多演示。这里推荐一个演示
http://home.dei.polimi.it/matteucc/Clustering/tutorial_html/AppletKM.html
操作是,鼠标左键是初始化点,右键初始化“种子点”,然后勾选“Show History”可以看到一步一步的迭代。
注:这个演示的链接也有一个不错的 K Means Tutorial 。
K-Means ++ 算法
K-Means主要有两个最重大的缺陷——都和初始值有关:
- K 是事先给定的,这个 K 值的选定是非常难以估计的。很多时候,事先并不知道给定的数据集应该分成多少个类别才最合适。( ISODATA 算法通过类的自动合并和分裂,得到较为合理的类型数目 K)
- K-Means算法需要用初始随机种子点来搞,这个随机种子点太重要,不同的随机种子点会有得到完全不同的结果。(K-Means++算法可以用来解决这个问题,其可以有效地选择初始点)
我在这里重点说一下 K-Means++算法步骤:
- 先从我们的数据库随机挑个随机点当“种子点”。
- 对于每个点,我们都计算其和最近的一个“种子点”的距离D(x)并保存在一个数组里,然后把这些距离加起来得到Sum(D(x))。
- 然后,再取一个随机值,用权重的方式来取计算下一个“种子点”。这个算法的实现是,先取一个能落在Sum(D(x))中的随机值Random,然后用Random -= D(x),直到其<=0,此时的点就是下一个“种子点”。
- 重复第(2)和第(3)步直到所有的K个种子点都被选出来。
- 进行K-Means算法。
相关的代码你可以在这里找到“implement the K-means++ algorithm”(墙) 另,Apache 的通用数据学库也实现了这一算法
K-Means 算法应用
看到这里,你会说,K-Means算法看来很简单,而且好像就是在玩坐标点,没什么真实用处。而且,这个算法缺陷很多,还不如人工呢。是的,前面的例子只是玩二维坐标点,的确没什么意思。但是你想一下下面的几个问题:
1)如果不是二维的,是多维的,如5维的,那么,就只能用计算机来计算了。
2)二维坐标点的X, Y 坐标,其实是一种向量,是一种数学抽象。现实世界中很多属性是可以抽象成向量的,比如,我们的年龄,我们的喜好,我们的商品,等等,能抽象成向量的目的就是可以让计算机知道某两个属性间的距离。如:我们认为,18岁的人离24岁的人的距离要比离12岁的距离要近,鞋子这个商品离衣服这个商品的距离要比电脑要近,等等。
只要能把现实世界的物体的属性抽象成向量,就可以用K-Means算法来归类了。
在 《k均值聚类(K-means)》 这篇文章中举了一个很不错的应用例子,作者用亚洲15支足球队的2005年到1010年的战绩做了一个向量表,然后用K-Means把球队归类,得出了下面的结果,呵呵。
- 亚洲一流:日本,韩国,伊朗,沙特
- 亚洲二流:乌兹别克斯坦,巴林,朝鲜
- 亚洲三流:中国,伊拉克,卡塔尔,阿联酋,泰国,越南,阿曼,印尼
其实,这样的业务例子还有很多,比如,分析一个公司的客户分类,这样可以对不同的客户使用不同的商业策略,或是电子商务中分析商品相似度,归类商品,从而可以使用一些不同的销售策略,等等。
最后给一个挺好的算法的幻灯片:http://www.cs.cmu.edu/~guestrin/Class/10701-S07/Slides/clustering.pdf
(全文完)
(转载本站文章请注明作者和出处 酷 壳 – CoolShell ,请勿用于任何商业用途)




 (24 人打了分,平均分: 4.25 )
(24 人打了分,平均分: 4.25 )
《K-Means 算法》的相关评论
+1 难道dij不是代表i到j的距离??
“这个算法很简单,但是有些细节我要提一下,求距离的公式我不说了,大家有初中毕业水平的人都应该知道怎么算的。”
有些情况下”距离“可以用欧式距离,有些情况不是应该用余弦之类的,此处不需要稍微说明一下咩
正好我也想说这一句。
距离这个东西,是可以自定义的。
@爱玛
内容有无。三个distance是距离公式。不是点群中点公式
Olin jo luopunut toivosta pravdan ja iltaroskalehtien ym. Turun Sanomien suhteen. Mutta sitten ilmestyi Appelsin. Tervetuloa vaan Appelsiini sinne väärää todista lähimmäisistään jakavien viitevasurirahmittajien laumaan.
“我这里想告诉大家另三个求中心点的的公式”
— 这三个公式应该是算距离,不是求中心点。
闵可夫斯基距离那里有一些问题。