rsync 的核心算法
rsync是unix/linux下同步文件的一个高效算法,它能同步更新两处计算机的文件与目录,并适当利用查找文件中的不同块以减少数据传输。rsync中一项与其他大部分类似程序或协定中所未见的重要特性是镜像是只对有变更的部分进行传送。rsync可拷贝/显示目录属性,以及拷贝文件,并可选择性的压缩以及递归拷贝。rsync利用由Andrew Tridgell发明的算法。这里不介绍其使用方法,只介绍其核心算法。我们可以看到,Unix下的东西,一个命令,一个工具都有很多很精妙的东西,怎么学也学不完,这就是Unix的文化啊。
本来不想写这篇文章的,因为原先发现有很多中文blog都说了这个算法,但是看了一下,发现这些中文blog要么翻译国外文章翻译地非常烂,要么就是介绍这个算法介绍得很乱让人看不懂,还有错误,误人不浅,所以让我觉得有必要写篇rsync算法介绍的文章。(当然,我成文比较仓促,可能会有一些错误,请指正)
目录
问题
首先, 我们先来想一下rsync要解决的问题,如果我们要同步的文件只想传不同的部分,我们就需要对两边的文件做diff,但是这两个问题在两台不同的机器上,无法做diff。如果我们做diff,就要把一个文件传到另一台机器上做diff,但这样一来,我们就传了整个文件,这与我们只想传输不同部的初衷相背。
于是我们就要想一个办法,让这两边的文件见不到面,但还能知道它们间有什么不同。这就出现了rsync的算法。
算法
rsync的算法如下:(假设我们同步源文件名为fileSrc,同步目的文件叫fileDst)
1)分块Checksum算法。首先,我们会把fileDst的文件平均切分成若干个小块,比如每块512个字节(最后一块会小于这个数),然后对每块计算两个checksum,
- 一个叫rolling checksum,是弱checksum,32位的checksum,其使用的是Mark Adler发明的adler-32算法,
- 另一个是强checksum,128位的,以前用md4,现在用md5 hash算法。
为什么要这样?因为若干年前的硬件上跑md4的算法太慢了,所以,我们需要一个快算法来鉴别文件块的不同,但是弱的adler32算法碰撞概率太高了,所以我们还要引入强的checksum算法以保证两文件块是相同的。也就是说,弱的checksum是用来区别不同,而强的是用来确认相同。(checksum的具体公式可以参看这篇文章)
2)传输算法。同步目标端会把fileDst的一个checksum列表传给同步源,这个列表里包括了三个东西,rolling checksum(32bits),md5 checksume(128bits),文件块编号。
我估计你猜到了同步源机器拿到了这个列表后,会对fileSrc做同样的checksum,然后和fileDst的checksum做对比,这样就知道哪些文件块改变了。
但是,聪明的你一定会有以下两个疑问:
- 如果我fileSrc这边在文件中间加了一个字符,这样后面的文件块都会位移一个字符,这样就完全和fileDst这边的不一样了,但理论上来说,我应该只需要传一个字符就好了。这个怎么解决?
- 如果这个checksum列表特别长,而我的两边的相同的文件块可能并不是一样的顺序,那就需要查找,线性的查找起来应该特别慢吧。这个怎么解决?
很好,让我们来看一下同步源端的算法。
3)checksum查找算法。同步源端拿到fileDst的checksum数组后,会把这个数据存到一个hash table中,用rolling checksum做hash,以便获得O(1)时间复杂度的查找性能。这个hash table是16bits的,所以,hash table的尺寸是2的16次方,对rolling checksum的hash会被散列到0 到 2^16 – 1中的某个整数值。(对于hash table,如果你不清楚,建议回去看大学时的数据结构教科书)
顺便说一下,我在网上看到很多文章说,“要对rolling checksum做排序”(比如这篇和这篇),这两篇文章都引用并翻译了原作者的这篇文章,但是他们都理解错了,不是排序,就只是把fileDst的checksum数据,按rolling checksum做存到2^16的hash table中,当然会发生碰撞,把碰撞的做成一个链表就好了。这就是原文中所说的第二步——搜索有碰撞的情况。
4)比对算法。这是最关键的算法,细节如下:
4.1)取fileSrc的第一个文件块(我们假设的是512个长度),也就是从fileSrc的第1个字节到第512个字节,取出来后做rolling checksum计算。计算好的值到hash表中查。
4.2)如果查到了,说明发现在fileDst中有潜在相同的文件块,于是就再比较md5的checksum,因为rolling checksume太弱了,可能发生碰撞。于是还要算md5的128bits的checksum,这样一来,我们就有 2^-(32+128) = 2^-160的概率发生碰撞,这太小了可以忽略。如果rolling checksum和md5 checksum都相同,这说明在fileDst中有相同的块,我们需要记下这一块在fileDst下的文件编号。
4.3)如果fileSrc的rolling checksum 没有在hash table中找到,那就不用算md5 checksum了。表示这一块中有不同的信息。总之,只要rolling checksum 或 md5 checksum 其中有一个在fileDst的checksum hash表中找不到匹配项,那么就会触发算法对fileSrc的rolling动作。于是,算法会住后step 1个字节,取fileSrc中字节2-513的文件块要做checksum,go to (4.1) – 现在你明白什么叫rolling checksum了吧。
4.4)这样,我们就可以找出fileSrc相邻两次匹配中的那些文本字符,这些就是我们要往同步目标端传的文件内容了。
rolling checksum算法
这个算法很简单,也叫Rabin-Karp 算法,由 Richard M. Karp 和 Michael O. Rabin 在 1987 年发表,它也是用来解决多模式串匹配问题的。其最大的精髓是,当我们往后面step 1个字符的时候,不用全部重新计算所有的checksum,也就是说,我们从 [0, 512] rolling 到 [1, 513] 时,我们不需要重新计算从1到513的checksum,而是重用 [0,512]的checksum直接算出来。
这个算法比较简单,我举个例子,我们有一个数字:12345678,假设我们以5个长度作为一个块,那么,第一个块就是 12345 ,12345可以表示为:
1 * 10^4 + 2 * 10^3 + 3 * 10^2 + 4 * 10^1 + 5 * 10^0 = 12345
如果我们要step 1步,也就是要得到 23456, 我们不必计算:
2 * 10^4 + 3 * 10^3 + 4 * 10^2 + 5 * 10^1 + 6 * 10^0
而是直接计算:
(12345 - 1 * 10^4) * 10 + 6 * 10 ^0
我们可以看到,其中,我们把12345最左边第一位去掉,然后,再加上最右边的一位。这就是Rolling checksum的算法。
实际的公式是:
hash ( t[0, m-1] ) = t[0] * b^(m-1) + t[1] * b^[m-2] ..... t[m-1] * b^0
其中的 b是一个常数基数,在 Rabin-Karp 算法中,我们一般取值为 256。
于是,在计算 hash ( t[1, m] ) 时,只需要下面这样就可以了:
hash( t[1, m] ) = hash ( t[0, m-1] ) - t[0] * b^(m-1) + t[m] * b ^0
图示
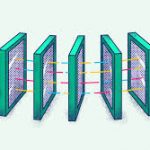
怎么,你没看懂? 好吧,我送佛送上西,画个示意图给你看看(对图中的东西我就不再解释了)。

这样,最终,在同步源这端,我们的rsync算法可能会得到下面这个样子的一个数据数组,图中,红色块表示在目标端已匹配上,不用传输(注:我专门在其中显示了两块chunk #5,相信你会懂的),而白色的地方就是需要传输的内容(注意:这些白色的块是不定长的),这样,同步源这端把这个数组(白色的就是实际内容,红色的就放一个标号)压缩传到目的端,在目的端的rsync会根据这个表重新生成文件,这样,同步完成。

最后想说一下,对于某些压缩文件使用rsync传输可能会传得更多,因为被压缩后的文件可能会非常的不同。对此,对于gzip和bzip2这样的命令,记得开启 “rsyncalbe” 模式。
(全文完,转载时请注明作者和出处)
(转载本站文章请注明作者和出处 酷 壳 – CoolShell ,请勿用于任何商业用途)




 (42 人打了分,平均分: 4.48 )
(42 人打了分,平均分: 4.48 )
《rsync 的核心算法》的相关评论
是的。但这并不会变成很大的负担。
因为,不相同的恰恰正是需要传过去的;故,读512字节,不同,传过去;再读,还不同,继续传……如此反复,一旦遇到一样的就可以只传索引;全都不一样就全传。
整个算法只需对整个文件做一次rolling checksum,这个复杂度是O(N)的,并不高。且由于CPU速度问题,预估最终执行时间和直接拷贝相比几乎无差别(当然,一旦有一致的块,就可以省去网络传输消耗了)。
感谢楼主,正好在做云同步,要用到这个。有没其他资料,给介绍介绍呗,嘿嘿
rolling checksum的精髓是(k+1,k+513)的checksum可以通过(k,k+512)的checksum O(1)算出来,从头算的话,这一块很容易成为瓶颈的
每个字节的偏移都需要rolling checksum, 这要计算rolling checksum (文件字节数-512) 次.
即使计算弱checksum, 如果要计算这么多次, 耗cpu估计是相当恐怖的.
是不是rolling checksum有什么玄机, 能省却一些计算?
最差的情况下,如果每个块都不断地rolling,那是不是性能上的消耗也挺大呢。
另一方面,如果本身文件就不大,直接传过来本地比较,是不是会更快呢。
学习了。节省了带宽,会不会牺牲了cpu资源?
fileDst:1,2,3,4;fileSrc:1,A,2,3,4; 假设,fileDst分块为 1,2;3,4 那么只会认为3,4是相同的,而实际上,2,3,4都是相同的。fileDst的分块按平均会不会太粗糙了,可不可以用rolling算法来分块呢
这篇文章并没有说出最核心的地方。其实只要简单的想一想,假如文件完全不相同,按照本文的说法,在检验的时候每个字节都会roll一次,重新算一遍checksum,你这个文件有多少字节你就要计算多少个checksum,这是非常恐怖的运算量。所以真正的精髓在于roll一次之后如何不用重新计算checksum,而是仅仅在原有checksum的基础上进行调整就可以得出新的checksum。
所以说整个rsync算法的核心精髓就在这个弱校验算法上。如何在向后滚动一个字节的情况下利用之前的checksum快速得到滚动之后的checksum,而这篇文章讲了这么多仅仅是外层的一些运作流程罢了。纠结hash和sort也是没什么意义的,这个本来只是实现方式上的选择而已。hash在碰撞较少的时候可以比sort效率高一些而已,用sort未尝不可。
@陈皓
没这么夸张吧,windows下也会用到类似diff的软件呀。只要是程序员,都会用到svn等版本管理工具,那么必然会用到diff。
正好毕设在做云同步系统,受用了,讲的比原文易懂。
在检验的时候每个字节都会roll一次,重新算一遍checksum,你这个文件有多少字节你就要计算多少个checksum,这是非常恐怖的运算量。所以真正的精髓在于roll一次之后如何不用重新计算checksum,而是仅仅在原有checksum的基础上进行调整就可以得出新的checksum。
我数学不是很好,不过那个弱校验的checksum算法应该就是你说的这个样子的吧。
肯定会,算法的本质就是怎么去合理利用资源,要么用时间换空间,要么用空间换时间@小邓
看来我的猜测 没错, 以我的例子 做2g 次比较,那岂不是要做死了人,什么cpu 很快,基本的结果就是负载非常的大,但是rsync 的场景应该是 少量变化,用这种算法应该还是很好的。
@陈皓
我想这不是思维认知问题,这是符号和意义绑定惯例的问题,往前一般约定都是往阅读的前进方向吧。
另外,我刚开始接触计算机的时候,对向前/后兼容有弄糊涂过。因为这个前/后有两种解释。。。
没这么夸张吧,windows下也会用到类似diff的软件呀。只要是程序员,都会用到svn等版本管理工具,那么必然会用到diff。tltesoft.com xinour.com
既然是從Wikipedia上翻譯過來的,應該也會在文內看到這一段吧
http://en.wikipedia.org/wiki/Rsync#Algorithm
“the rolling checksum of bytes n+1 through n+s can be computed from R, byte n, and byte n+s without having to examine the intervening bytes.”
把這關鍵的設計漏掉,這篇文章等同於宣稱rsync是個暴力到不行的低效率解法。
@陈皓
第一个点中,弱的checksum是用来区别不同,而强的是用来确认相同 这句话怎么理解呢?我怎么觉得是反过来的呢?请解答一下,谢谢!
好吧,我又理解这句话了。。。
@萱琪
@陈皓
The weak rolling checksum used in the rsync algorithm needs to have the property that it is very cheap to calculate the checksum of a buffer X2 .. Xn+1 given the checksum of buffer X1 .. Xn and the values of the bytes X1 and Xn+1. from http://rsync.samba.org/tech_report/node3.html,rolling checksum算法本身就是利用了前后两次checksum的一些相关性来实现快速计算的
tltesoft.com xinour.com在检验的时候每个字节都会roll一次,重新算一遍checksum,你这个文件有多少字节你就要计算多少个checksum,这是非常恐怖的运算量。所以真正的精髓在于roll一次之后如何不用重新计算checksum,而是仅仅在原有checksum的基础上进行调整就可以得出新的checksum。
rolling checksum 算法最精华的位置没有说到,咋一看会让人觉得rsync是一种非常暴力低效率的办法.
Windows 下的扫雷纸牌计算器也有很多精妙的东西, 你们 unix 粉是不是认为轮子也是用 unix 文化发明的啊
精彩
这种应用,应该是在作者已经知道,文件的之间有细微差别的情况下使用的,如果是两个完全不同的文件,就没有必要用了.
所以应该强调一下应用场合.
看来我的猜测 没错, 以我的例子 做2g 次比较,那岂不是要做死了人,什么cpu 很快,基本的结果就是负载非常的大,但是rsync 的场景应该是 少量变化,用这种算法应该还是很好的。
真还不是很懂
请教楼主,文件的双向同步原理?
非常不错。不过rsync还是单线程的同步。要是能多线程就更快了
@余镇源
所谓文件双向同步,其实是加了“文件版本号(时间戳)”和“版本号(时间戳)碰撞处理机制”的文件单向同步吧?否则无法判断以哪一个文件为准。
以文本文件为例,同一个文件,这边的内容是“ABCDEF”,那边的内容是“UVWXYZ”,如何“双向同步”?