Linus:利用二级指针删除单向链表
感谢网友full_of_bull投递此文(注:此文最初发表在这个这里,我对原文后半段修改了许多,并加入了插图)
Linus大婶在slashdot上回答一些编程爱好者的提问,其中一个人问他什么样的代码是他所喜好的,大婶表述了自己一些观点之后,举了一个指针的例子,解释了什么才是core low-level coding。
下面是Linus的教学原文及翻译——
“At the opposite end of the spectrum, I actually wish more people understood the really core low-level kind of coding. Not big, complex stuff like the lockless name lookup, but simply good use of pointers-to-pointers etc. For example, I’ve seen too many people who delete a singly-linked list entry by keeping track of the “prev” entry, and then to delete the entry, doing something like。(在这段话的最后,我实际上希望更多的人了解什么是真正的核心底层代码。这并不像无锁文件名查询(注:可能是git源码里的设计)那样庞大、复杂,只是仅仅像诸如使用二级指针那样简单的技术。例如,我见过很多人在删除一个单项链表的时候,维护了一个”prev”表项指针,然后删除当前表项,就像这样)”
if (prev)
prev->next = entry->next;
else
list_head = entry->next;
and whenever I see code like that, I just go “This person doesn’t understand pointers”. And it’s sadly quite common.(当我看到这样的代码时,我就会想“这个人不了解指针”。令人难过的是这太常见了。)
People who understand pointers just use a “pointer to the entry pointer”, and initialize that with the address of the list_head. And then as they traverse the list, they can remove the entry without using any conditionals, by just doing a “*pp = entry->next”. (了解指针的人会使用链表头的地址来初始化一个“指向节点指针的指针”。当遍历链表的时候,可以不用任何条件判断(注:指prev是否为链表头)就能移除某个节点,只要写)
*pp = entry->next
So there’s lots of pride in doing the small details right. It may not be big and important code, but I do like seeing code where people really thought about the details, and clearly also were thinking about the compiler being able to generate efficient code (rather than hoping that the compiler is so smart that it can make efficient code *despite* the state of the original source code). (纠正细节是令人自豪的事。也许这段代码并非庞大和重要,但我喜欢看那些注重代码细节的人写的代码,也就是清楚地了解如何才能编译出有效代码(而不是寄望于聪明的编译器来产生有效代码,即使是那些原始的汇编代码))。
Linus举了一个单向链表的例子,但给出的代码太短了,一般的人很难搞明白这两个代码后面的含义。正好,有个编程爱好者阅读了这段话,并给出了一个比较完整的代码。他的话我就不翻译了,下面给出代码说明。
如果我们需要写一个remove_if(link*, rm_cond_func*)的函数,也就是传入一个单向链表,和一个自定义的是否删除的函数,然后返回处理后的链接。
这个代码不难,基本上所有的教科书都会提供下面的代码示例,而这种写法也是大公司的面试题标准模板:
typedef struct node
{
struct node * next;
....
} node;
typedef bool (* remove_fn)(node const * v);
// Remove all nodes from the supplied list for which the
// supplied remove function returns true.
// Returns the new head of the list.
node * remove_if(node * head, remove_fn rm)
{
for (node * prev = NULL, * curr = head; curr != NULL; )
{
node * const next = curr->next;
if (rm(curr))
{
if (prev)
prev->next = next;
else
head = next;
free(curr);
}
else
prev = curr;
curr = next;
}
return head;
}
这里remove_fn由调用查提供的一个是否删除当前实体结点的函数指针,其会判断删除条件是否成立。这段代码维护了两个节点指针prev和curr,标准的教科书写法——删除当前结点时,需要一个previous的指针,并且还要这里还需要做一个边界条件的判断——curr是否为链表头。于是,要删除一个节点(不是表头),只要将前一个节点的next指向当前节点的next指向的对象,即下一个节点(即:prev->next = curr->next),然后释放当前节点。
但在Linus看来,这是不懂指针的人的做法。那么,什么是core low-level coding呢?那就是有效地利用二级指针,将其作为管理和操作链表的首要选项。代码如下:
void remove_if(node ** head, remove_fn rm)
{
for (node** curr = head; *curr; )
{
node * entry = *curr;
if (rm(entry))
{
*curr = entry->next;
free(entry);
}
else
curr = &entry->next;
}
}
同上一段代码有何改进呢?我们看到:不需要prev指针了,也不需要再去判断是否为链表头了,但是,curr变成了一个指向指针的指针。这正是这段程序的精妙之处。(注意,我所highlight的那三行代码)
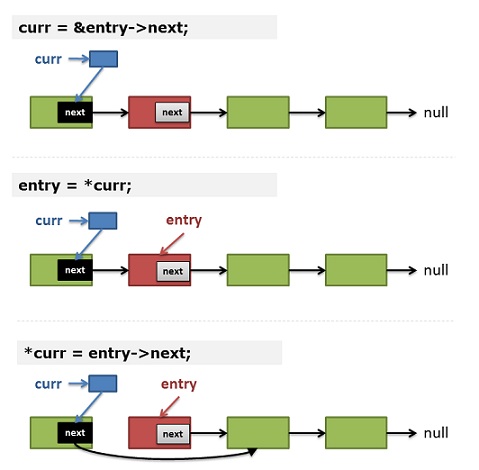
让我们来人肉跑一下这个代码,对于——
- 删除节点是表头的情况,输入参数中传入head的二级指针,在for循环里将其初始化curr,然后entry就是*head(*curr),我们马上删除它,那么第8行就等效于*head = (*head)->next,就是删除表头的实现。
- 删除节点不是表头的情况,对于上面的代码,我们可以看到——
1)(第12行)如果不删除当前结点 —— curr保存的是当前结点next指针的地址。
2)(第5行) entry 保存了 *curr —— 这意味着在下一次循环:entry就是prev->next指针所指向的内存。
3)(第8行)删除结点:*curr = entry->next; —— 于是:prev->next 指向了 entry -> next;
是不是很巧妙?我们可以只用一个二级指针来操作链表,对所有节点都一样。
如果你对上面的代码和描述理解上有困难的话,你可以看看下图的示意:
(全文完)
(转载本站文章请注明作者和出处 酷 壳 – CoolShell ,请勿用于任何商业用途)







 (57 人打了分,平均分: 4.25 )
(57 人打了分,平均分: 4.25 )
《Linus:利用二级指针删除单向链表》的相关评论
哈哈哈,Linus大婶,是故意的吗?
有一处翻译觉得不太对:
rather than hoping that the compiler is so smart that it can make efficient code *despite* the state of the original source code
应该是
而不是寄望于聪明的编译器来产生高效的代码,即使源代码很糟糕
efficient是有效率的,不是有效的;original source code和汇编没什么关系吧
翻译倒是看得很认真。有关original source code,我想linus大神是想表达“有些程序员期待compiler能从低效的源代码中翻译出高效的汇编指令”吧@wwwjfy
第三幅图,让curr直接指到entry的next上,是不是更恰当一些~~~~
@Luckyvan 嗯,意思一样。怎么翻译就是“雅”的问题了。
这一句翻译也有问题
At the opposite end of the spectrum
按照原文翻译是“在谱的另一端”,如果意译的话,实际上是说“与conventional high-level coding相对的另一端,也即core low-level coding”
且不说链表指针什么的, 很多连 return 都不知道怎么摆好的程序员一堆, 经常能看到这样的代码
if xxx return true;
else return false;
@Neuron Teckid
你是想说应该
if xxx return true;
return false;
还是
bool ret = false;
if xxx ret = true;
return ret;
其实个人感觉这只是代码风格的问题,反而感觉
if xxx return true;
else return false;
更具有可读性,当然我都是写成
if xxx return true;
return false;
@Neuron Teckid
或者直接 return xxx;
本质就是引入一个虚拟的头,简化处理原来的额外判断
很喜欢博主的文章,刚刚用豆约翰博客备份专家备份了您的全部博文。
@Luckyvan
entry是要free掉的,curr怎么能直接指到entry的next上,原图没错
我稍微比较了两种做法在运行方面的差距。
core 2 Duo E8400上,gcc4.6.1 -O2,用cachegrind运行,大致的结论是这样的:
– 当删除的几率很低时,Linus的做法在icache和dcache上的表现都好得多。每次循环比另一种做法少运行3个指令,少1次内存写入。
– 当删除的几率很高时,情况则倒过来了:另一种做法,在每次循环时,少运行2个指令,少1次内存读取,少1次内存写入
– 当删除的几率接近50%时,情况比较微妙:Linus的做法,在每2次循环时,少运行1个指令。另一种做法,在每2次循环是,少1次内存读取。
– cache miss rate在各种情况下都差不多。
相关code在https://gist.github.com/4704935
考虑到Linus的做法更简洁,我还是更喜欢他的。
确实直观了些, 根本原因是我们不用关心prev是什么, 只需要关心prev->next是对的就可以了(是prev的next, 也指向了正确的next)
第一段翻译有点问题。『我见过很多人在删除一个单项链表的时候』 =>『我见过很多人在删除一个单项链表表项的时候』
@garry
直接return xxx;不就好了
“大婶”是“大神”的谐音,考虑到大神近年发福,而且性格彪悍,故取此号。我的笔名也是取自其粗口:http://coolshell.cn/articles/1724.html
以上纯属无聊,@wwwjfy @Luckyvan “original source code”的确是指汇编代码,之前用*despite*强调过。最初的操作系统使用的就是汇编,比如Linux最初就是AT&T语言+gas汇编(也有部分是as86),对于黑客——特别是内核黑客圈内来说,只有汇编语言才算得上严格意义上的源代码hacking。程序运行性能也以汇编指令为标准,所以@ZFang 我不知道你的测试结果是否同你的硬件平台和编译器及其编译选项(-O2)有关?
@Luckyvan 感谢您的精细纠正,不看上下文还真不明白啥意思~
还要感谢一下@陈皓 ,这是我初次投稿,感觉他真的是对每一篇博文高质量要求,都是一字一句地改。我是上周五投稿的,周末他很忙,但我看修改记录都是在半夜12点——虽然大部分修改都是删除T T,插图做得很漂亮,以后我会将稿件写得尽量精简。
我会再接再厉,最后感谢大家支持,欢迎你们来oldlinux论坛玩玩~
这个我一个月前在reddit上也看到了,也写了篇[博客](http://blog-mking.rhcloud.com/2013/01/11/linus%E5%A4%A7%E7%A5%9E%E8%AF%B4%E4%BD%A0%E4%B8%8D%E6%87%82%E6%8C%87%E9%92%88/) ,感觉没有作者写的好,还需要多练习写博客。当时在reddit上讨论的很激烈。有人反对这么实现,说是影响代码可读性,还有人做实验对比了两种实现的效率。从这件事看出国外的技术氛围,Linus虽然是神一般的人物了,他提出的技术观点反对的也不少。
一般这种链表问题,好像加一个dummy head比较好吧,比如
struct Node{ int val; Node* next; Node(int v){ val = v; next = NULL; } }; typedef bool (* remove_fn)(int val) ; Node* remove_if(Node* head, remove_fn f) { Node *r=new Node(0); Node *p=r; while(head) { if(!f(head->val)){ p->next = head; p=p->next; head = head->next; p->next=NULL; }else{ Node* t=head; head=head->next; delete t; } } p=r; r=r->next; delete p;//remove dummy head return r; }。。评论里怎么加代码啊。。
Linus的这个用法,是利用了链表的一个特性:当这样来定义struct,
typedef struct node
{
struct node * next;
….
}
即指针next是在struct的最前面时,next指针的存放地址,就等于是这个node本身的存放地址,即
node == &node->next
因此那一句
curr = &entry->next;
也可以写成
curr = (node**)entry;
这个特性,也成了利用二级指针的关键。
如果链表是这样定义的,linus的做法就行不通了。然而在kernel代码里没人会这样定义链表:
typedef struct node
{
….
struct node * next;
}
@fiull_of_bullshit
我觉得original source code这一句的翻译就是“而不是指望编译器聪明到不管什么样子的源代码都能够生成高效的代码”。efficient的意思就是高效而不是有效,这个查查字典就知道了,至于despite的意思比较微妙,我不知道要怎么说才好,虽然中文翻译是“尽管”,但这里如果是按照你的意思应该用even而不是despite。而且我从来没见过有人用original source code这种说法来形容汇编代码。这里的original应该是相对于编译器优化过后生成的代码。原本他的意思就是有人知道怎么写才能使编译器生成高效的代码,而有的人则是指望编译器来帮他优化代码。
以上纯属个人观点。
@full_of_bull
恩,编译器跟运行效率当然会有关系。不过对于这两种做法而言,我不认为我能写出比gcc 4.6.1 -O2运行效率更高的汇编了。编译器虽然不能帮你把某种算法给优化成更好的算法(比如把选择排序优化成快排),不过在编译这些普通的程序的时候,做的当然是比人做的要更好的。
@card323
见9L
看了,这篇文章,一直在想,二级指针究竟是凭什么在这个问题上比一级指针牛?
于是,写了下面的程序,也只用一个变量,可是多了个while循环,相当于一级指针中判断表头的功能;可是,这东西在二级指针里面怎么就避免了?二级指针比一级指针多了什么?
二级指针可以保存更多信息?
node* remove_if(node * head, remove_fn rm) { if (head== null) return; while(rm(head)) { node* curr = head; head = head->next; free(curr); } for (node* pre = head; pre->next; ) { node * curr = pre->next; if (rm(curr)) { pre->next = curr->next; free(curr); } else pre = curr; } return head; }是不是二级指针可以通过反引用改变一个结构体中的next指针,而一级指针做不到这点?要用一级指针就必须保存一个pre指针?
太复杂了;其实就想知道,有时候用二级指针比一级指针好;可是这个‘时候’有没有一个模式,有没有一个一般的表达方式,除了删除链表节点这种‘时候’,还有没有其他的‘时候’?
因此,对于程序优化策略来讲,量化分析仍然是最有效的一条路子?@ZFang
总感觉插图是错的。。。curr不是一直是和entry同步的么。。
@viho_he
不同意你的观点,链表操作只和next指针有关系,和内存布局有什么关系呢?
@Luckyvan
不对吧。entry是要删除的。所以它的next不存在了。
@ZFang
喜欢追究细节的人。
@viho_he
Linus的这个程序和你说的那个特性貌似没什么关系吧
你写的node == &node->next应该是想说&node == &node->next的意思吧
无论next指针在结构体中的定义位置 linux的程序都是没问题的吧
呵呵,俺来冒个泡
rather than hoping that the compiler is so smart that it can make efficient code *despite* the state of the original source code
个人觉得是,而不是希望编译器很聪明能够产生高效的代码(意指 汇编代码或者指令)也不顾及初始源代码的书写方式。也就是说编译器优化代码也是有局限性的,不是任何情况下都能做到做好。
整个总体意思应该是,高效的代码需要靠人,需要注重细节,懂得如何做能够生产出高效运行的代码,不是把这些都寄望于编译器。如果我们真的要把这些寄望于编译器,那也得懂得如何做,有利于编译器优化我们的代码。
个人观点,呵呵
Linux处理双链表的方式也让我觉得很惊艳。
参考:http://www.cs.fsu.edu/~baker/devices/lxr/http/source/linux/include/linux/list.h
container_of 宏:http://www.cs.fsu.edu/~baker/devices/lxr/http/source/linux/include/linux/kernel.h#L650
首先,双链表结构不含数据成员。而是反过来,结构体包含双链表成员。
然后,里面的那些遍历、插入等等都是宏操作,而且是宏里面又利用另外一个宏。
最后,取数据成员的那个宏也是精妙无比:
650 #define container_of(ptr, type, member) ({ \
651 const typeof( ((type *)0)->member ) *__mptr = (ptr); \
652 (type *)( (char *)__mptr – offsetof(type,member) );})
@wwwjfy
我觉得这个对
我觉得对于当时的语境来讲
这个 source code 可以是各种高级语言而不可能是汇编语言
虽然汇编也可能是程序员写出来的源代码
但是汇编不用编译 compile 只需要翻译
而且用高级语言编程 程序的细节会影响到最终的编译结果
Linus本来的意思我认为是
虽然用高级语言编程
但是也要注意程序的执行效率 Efficiency
而不能指望一个聪明的编译器替你完美优化所有代码
还有我觉得虽然称为内核黑客
但是并不是非要去写汇编代码
C 和 C++对底层的控制一样很好
只要你想这么写 知道怎么写
查看汇编代码只是为了查看运行效率
用汇编改内核我个人觉得不太现实
那么多支持的处理器 每次修改都要手工改汇编
看了好久才看懂,其实entry才是当前处理的节点,而curr存的是存的是prev信息,只不过它存的是指向prev的next的指针,因为删除当前节点只需要改变prev->next。但是list的第一个元素没有prev->next,怎么办呢?如果原来指向list头部的指针叫做pHead,那么可以把pHead看作是第一个元素的prev->next
看来的确是我错了,”original source code”就该翻成“原来的源代码”而不是汇编语言:P
@ZFang
谢谢你的细致,不过个人认为既然要比试coding,还是不要带O2这种外挂为好。大婶都说了不要依赖编译器的聪明,虽然实际应用中编译器比程序员功劳大得多,但这种调优的结果对程序员来说是不可预测的,也许优化效果还要依赖于平台。所以这里麻烦你去掉O2再测一次,让我们公正地评价二级指针带来的效果。
next在内存布局里的位置我后来想了一下,的确和代码无关,但next放在对象基址上,遍历时整个链表时CPU可以少做一次偏移地址寻址操作,不知道实际效果是否这样,也许在O2面前任何源代码都是浮云。
@einmus
Linux的list.h是个创举,遗憾的是我们已经无法考察谁发明了它。我想其伟大之处在于借鉴了C++里的OO,将链接行为抽象为一个对象,从而可以用在所有结构体里面而根本不必考虑它是怎样实现的。而且现代内核源码里数据结构几乎都改装成双链表了,我本人也从实践中体会其精妙之处。本来想专门写一篇文章探讨,但发现网上资料太多,比如《深入浅出Linux内核双向链表》就论述得几近完美,只能割爱了。在享受编程技术之成熟带来种种便利的今天,我也感受到写一篇原创性技术博文又是何其难!
当初在live555开源代码中看到二级指针删除链表结点的方法,就很赞叹其用法。原来取自linux。
同赞 Linux的list.h是个创举。。。
关于这个,我写了篇文章欢迎各位点评:
http://www.thoughts-of.me/index.php?id=381
说白了就是:传统方法我们操作的是Node 节点。博主的方法操作的是Node->next,输入也发生了改变,假设有一个next指向头指针,我们传入的就是这个不在链表范围内的next的地址。
博主方法的current变量,实际上是待分析结点的前一个next的地址。
@erben
应该说,current解引用的值和entry是同步的。
个人更喜欢
return xxx ? true : false;
@Neuron Teckid
关于链表我还想吐槽几句,假如有一天你去应聘程序员,面试官给你一个题目要你写一个链表排序神马的,你干脆直接写一个”#include “然后当着他的面说你out了!是的,我们的题库out了,我们的教科书也out了,更悲剧的不单单是out,而是out十多年了还要继续out下去,结果长大以后连一段二级指针代码都理解得这么困难。。。
我感觉文章解释得有点复杂了:)显然二级指针是保存了可能会被修改的变量的地址,这就是head或prev->next。通过二级指针,head或prev->next这两个概念被统一在一起。
呵呵,本来是很简单,二级指针是指向指针的指针,牢记这一点就知道*curr引用的是什么了,可惜耗子说这样写博太简单。所以没必要细看博文,心里归纳着就行。@Alomega
谢谢你的Blog也说的很明白@t.k.
我也是这么觉得的。。。entry应该和*curr指向同一个结点吧
@shengy
恩,是我弄错了,图和解释都是对的:)