Linus:为何对象引用计数必须是原子的
(感谢网友 @我的上铺叫路遥 投稿)
Linus大神又在rant了!这次的吐槽对象是时下很火热的并行技术(parellism),并直截了当地表示并行计算是浪费所有人时间(“The whole “let’s parallelize” thing is a huge waste of everybody’s time.”)。大致意思是说乱序性能快、提高缓存容量、降功耗。当然笔者不打算正面讨论并行的是是非非(过于宏伟的主题),因为Linus在另一则帖子中举了对象引用计数(reference counting)的例子来说明并行的复杂性。
在Linus回复之前有人指出对象需要锁机制的情况下,引用计数的原子性问题:
Since it is being accessed in a multi-threaded way, via multiple access paths, generally it needs its own mutex — otherwise, reference counting would not be required to be atomic and a lock of a higher-level object would suffice.
由于(对象)通过多线程方式及多种获取渠道,一般而言它需要自身维护一个互斥锁——否则引用计数就不要求是原子的,一个更高层次的对象锁足矣。
而Linus不那么认为:
The problem with reference counts is that you often need to take them *before* you take the lock that protects the object data.
引用计数的问题在于你经常需要在对象数据上锁保护之前完成它。
The thing is, you have two different cases:
问题有两种情况:
– object *reference* 对象引用
– object data 对象数据
and they have completely different locking.
它们锁机制是完全不一样的。
Object data locking is generally per-object. Well, unless you don’t have huge scalability issues, in which case you may have some external bigger lock (extreme case: one single global lock).
对象数据保护一般是一个对象拥有一个锁,假设你没有海量扩展性问题,不然你需要一些外部大一点的锁(极端的例子,一个对象一个全局锁)。
But object *referencing* is mostly about finding the object (and removing/freeing it). Is it on a hash chain? Is it in a tree? Linked list? When the reference count goes down to zero, it’s not the object data that you need to protect (the object is not used by anything else, so there’s nothing to protect!), it’s the ways to find the object you need to protect.
但对象引用主要关于对象的寻找(移除或释放),它是否在哈希链,一棵树或者链表上。当对象引用计数降为零,你要保护的不是对象数据,因为对象没有在其它地方使用,你要保护的是对象的寻找操作。
And the lock for the lookup operation cannot be in the object, because – by definition – you don’t know what the object is! You’re trying to look it up, after all.
而且查询操作的锁不可能在对象内部,因为根据定义,你还不知道这是什么对象,你在尝试寻找它。
So generally you have a lock that protects the lookup operation some way, and the reference count needs to be atomic with respect to that lock.
因此一般你要对查询操作上锁,而且引用计数相对那个锁来说是原子的(译者注:查询锁不是引用计数所在的对象所有,不能保护对象引用计数,后面会解释为何引用计数变更时其所在对象不能上锁)。
And yes, that lock may well be sufficient, and now you’re back to non-atomic reference counts. But you usually don’t have just one way to look things up: you might have pointers from other objects (and that pointer is protected by the object locking of the other object), but there may be multiple such objects that point to this (which is why you have a reference count in the first place!)
当然这个锁是充分有效的,现在假设引用计数是非原子的,但你常常不仅仅使用一种方式来查询:你可能拥有其它对象的指针(这个指针又被其它对象的对象锁给保护起来),但同时还会有多个对象指向它(这就是为何你第一时间需要引用计数的理由)。
See what happens? There is no longer one single lock for lookup. Imagine walking a graph of objects, where objects have pointers to each other. Each pointer implies a reference to an object, but as you walk the graph, you have to release the lock from the source object, so you have to take a new reference to the object you are now entering.
看看会发生什么?查询不止存在一个锁保护。你可以想象走过一张对象流程图,其中对象存在指向其它对象的指针,每个指针暗含了一次对象引用,但当你走过这个流程图,你必须释放源对象的锁,而你进入新对象时又必须增加一次引用。
And in order to avoid deadlocks, you can not in the general case take the lock of the new object first – you have to release the lock on the source object, because otherwise (in a complex graph), how do you avoid simple ABBA deadlock?
而且为了避免死锁,你一般不能立即对新对象上锁——你必须释放源对象的锁,否则在一个复杂流程图里,你如何避免ABBA死锁(译者注:假设两个线程,一个是A->B,另一个B->;A,当线程一给A上锁,线程二给B上锁,此时两者谁也无法释放对方的锁)?
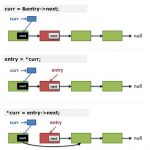
So atomic reference counts fix that. They work because when you move from object A to object B, you can do this:
原子引用计数修正了这一点,当你从对象A到对象B,你会这样做:
(a) you have a reference count to A, and you can lock A
对象A增加一次引用计数,并上锁。
(b) once object A is locked, the pointer from A to B is stable, and you know you have a reference to B (because of that pointer from A to B)
对象A一旦上锁,A指向B的指针就是稳定的,于是你知道你引用了对象B。
(c) but you cannot take the object lock for B (ABBA deadlock) while holding the lock on A
但你不能在对象A上锁期间给B上锁(ABBA死锁)。
(d) increment the atomic reference count on B
对象B增加一次原子引用计数。
(e) now you can drop the lock on A (you’re “exiting” A)
现在你可以扔掉对象A的锁(退出对象A)。
(f) your reference count means that B cannot go away from under you despite unlocking A, so now you can lock B.
对象B的原子引用计数意味着即使给A解锁期间,B也不会失联,现在你可以给B上锁。
See? Atomic reference counts make this kind of situation possible. Yes, you want to avoid the overhead if at all possible (for example, maybe you have a strict ordering of objects, so you know you can walk from A to B, and never walk from B to A, so there is no ABBA deadlock, and you can just lock B while still holding the lock on A).
看见了吗?原子引用计数使这种情况成为可能。是的,你想尽一切办法避免这种代价,比如,你也许把对象写成严格顺序的,这样你可以从A到B,绝不会从B到A,如此就不存在ABBA死锁了,你也就可以在A上锁期间给B上锁了。
But if you don’t have some kind of forced ordering, and if you have multiple ways to reach an object (and again – why have reference counts in the first place if that isn’t true!) then atomic reference counts really are the simple and sane answer.
但如果你无法做到这种强迫序列,如果你有多种方式接触一个对象(再一次强调,这是第一时间使用引用计数的理由),这样,原子引用计数就是简单又理智的答案。
If you think atomic refcounts are unnecessary, that’s a big flag that you don’t actually understand the complexities of locking.
如果你认为原子引用计数是不必要的,这就大大说明你实际上不了解锁机制的复杂性。
Trust me, concurrency is hard. There’s a reason all the examples of “look how easy it is to parallelize things” tend to use simple arrays and don’t ever have allocations or freeing of the objects.
相信我,并发设计是困难的。所有关于“并行化如此容易”的理由都倾向于使用简单数组操作做例子,甚至不包含对象的分配和释放。
People who think that the future is highly parallel are invariably completely unaware of just how hard concurrency really is. They’ve seen Linpack, they’ve seen all those wonderful examples of sorting an array in parallel, they’ve seen all these things that have absolutely no actual real complexity – and often very limited real usefulness.
那些认为未来是高度并行化的人一成不变地完全没有意识到并发设计是多么困难。他们只见过Linpack,他们只见过并行技术中关于数组排序的一切精妙例子,他们只见过一切绝不算真正复杂的事物——对真正的用处经常是非常有限的。
(译者注:当然,我无意借大神之口把技术宗教化。实际上Linus又在另一篇帖子中综合了对并行的评价。)
Oh, I agree. My example was the simple case. The really complex cases are much worse.
哦,我同意。我的例子还算简单,真正复杂的用例更糟糕。
I seriously don’t believe that the future is parallel. People who think you can solve it with compilers or programming languages (or better programmers) are so far out to lunch that it’s not even funny.
我严重不相信未来是并行的。有人认为你可以通过编译器,编程语言或者更好的程序员来解决问题,他们目前都是神志不清,没意识到这一点都不有趣。
Parallelism works well in simplified cases with fairly clear interfaces and models. You find parallelism in servers with independent queries, in HPC, in kernels, in databases. And even there, people work really hard to make it work at all, and tend to expressly limit their models to be more amenable to it (eg databases do some things much better than others, so DB admins make sure that they lay out their data in order to cater to the limitations).
并行计算可以在简化的用例以及具备清晰的接口和模型上正常工作。你发现并行在服务器上独立查询里,在高性能计算(High-performance computing)里,在内核里,在数据库里。即使如此,人们还得花很大力气才能使它工作,并且还要明确限制他们的模型来尽更多义务(例如数据库要想做得更好,数据库管理员得确保数据得到合理安排来迎合局限性)。
Of course, other programming models can work. Neural networks are inherently very parallel indeed. And you don’t need smarter programmers to program them either..
当然,其它编程模型倒能派上用场,神经网络(neural networking)天生就是非常并行化的,你不需要更聪明的程序员为之写代码。
参考资料
- Real World Technologies:Linus常去“灌水”的一个论坛,讨论未来机器架构(看名字就知道Linus技术偏好,及其之前对虚拟化技术(virtualization)的吐槽)
- 多线程程序中操作的原子性:解释为什么i++不是原子操作
- Concurrency Is Not Parallelism:Go语言之父Rob Pike幻灯片解释“并发”与“并行”概念上的区别
(全文完)
(转载本站文章请注明作者和出处 酷 壳 – CoolShell ,请勿用于任何商业用途)






 (42 人打了分,平均分: 3.83 )
(42 人打了分,平均分: 3.83 )
《Linus:为何对象引用计数必须是原子的》的相关评论
Linus大人干得漂亮。早就想吐槽朴素引用计数了。
其实,朴素的引用计数差劲,人们早就知道了,这也就是为什么学术界这么多年来一直没有人关心引用计数吧,高度优化的引用计数尚且比朴素的mark-sweep慢30%。当然,也有例外的突破,比如: http://users.cecs.anu.edu.au/~rifat/files/rc-ismm-2012.pdf 和 http://users.cecs.anu.edu.au/~rifat/files/rcix-oopsla-2013.pdf
我的感觉,现在的CPU已经不像人们以往想象的那样工作了。比如OoO什么的,让我脑子转了好久。
让我感到意外的是,并行好像不是新概念,但Linux到了200x年才有比较好的POSIX thread实现。
再补充一下,关于对象循环引用(cyclic graph)这样更复杂的情况,Linus做了如下回复,大意是说,单纯使用引用计数不够,需要综合解决方案,比如compare-and-exchange云云。笔者看不大理解就不翻译了,所以留给大家填充脑洞吧~
这句话“因此一般你要对查询操作上锁,而且引用计数相对那个锁来说是原子的”里面,不太理解“引用计数相对那个锁来说是原子的”是啥意思?
理解能力比较弱,没看明白为什么非原子的引用计数怎么导致了ABBA死锁?而原子引用计数怎么就解决这个问题了?
@passinger
Linus先说明两个概念:对象数据和对象引用,并且两者拥有不同的锁机制。
对象的引用计数属于对象内部data,理应由对象内部的锁保护起来。但引用计数的操作不属于对象,对象查询操作使用的外部锁无法保护引用计数,也就是说仍存在被其它引用入侵的风险,所以使用原子操作。
至于入侵的风险会是什么,见参考资料第二条。
ABBA死锁风险决定了当存在A->B执行序列时,A上锁期间B是不能上锁的,必须等到A退出。因而B的引用计数必须在B上锁之前完成,所以必须原子操作。
好高深啊,看不懂
感谢转贴 不太感谢翻译
a graph of objects 怎会是”对象流程图”的?
@mono
应该叫“对象关系图”比较合适
中文翻譯太晦澀了,還不如英文原文通俗易懂,難道是機器翻譯的?
(极端的例子,一个对象一个全局锁)这句翻译有误,应该是一共只有一个而不是一个对象一个
@wan
的确是失误,谢谢指正!
以前他不是也吐槽用C++的都是脑残么…
偶尔看一下提提神
哈哈,那我不学go了,让它去吧
关羽的美称!
不是这么固执的人也不能坚持这么长时间。
测试测试
谢谢分享。。。
有学习Solr的博客吗,给推荐一个。感激
@pythonwood
Go 才不是并行呢,goroutine只是并发而已。
而且Go提倡Share memory by channel, 就是不希望因操作同一对象徒增复杂度,而是把对象的操作交给一个特定的goroutine来完成。
请问关于javassist的文章能不能在你这里投稿?http://www.javafreer.com/%E5%9F%BA%E4%BA%8Ejavassist%E5%9C%A8jar%E5%8C%85%E4%B8%AD%E6%9F%A5%E6%89%BE%E7%9B%B8%E4%BA%92%E4%BE%9D%E8%B5%96%E5%85%B3%E7%B3%BB%E7%9A%84%E5%88%86%E6%9E%90%E5%B7%A5%E5%85%B7/
关于javassist判断编译出来的jar中方法之间的相互关系。 可以防止java调度的问题导致jar冲突
分析的很仔细,值得我们这些人学习。
博主有没有兴趣做友情链接啊,可以加扣扣联系:2396238979
不是很懂。。。
怎么去了阿里之后就不更新博客了?
被洗脑了?
objective-C笑而不语,人家ARC不是工作得很好嘛???? 不明白大神为什么要吐槽引用计数
@hoooo
是你理解力有问题,Linus 根本没吐槽引用计数。
Linus其实谈的就是ww_mutex的一个特例
(b) once object A is locked, the pointer from A to B is stable, and you know you have a reference to B (because of that pointer from A to B)
这句如何理解?为什么当A是LOCKED, 我们可以安全的引用B指针?