K Nearest Neighbor 算法
K Nearest Neighbor算法又叫KNN算法,这个算法是机器学习里面一个比较经典的算法, 总体来说KNN算法是相对比较容易理解的算法。其中的K表示最接近自己的K个数据样本。KNN算法和K-Means算法不同的是,K-Means算法用来聚类,用来判断哪些东西是一个比较相近的类型,而KNN算法是用来做归类的,也就是说,有一个样本空间里的样本分成很几个类型,然后,给定一个待分类的数据,通过计算接近自己最近的K个样本来判断这个待分类数据属于哪个分类。你可以简单的理解为由那离自己最近的K个点来投票决定待分类数据归为哪一类。
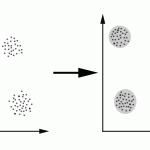
Wikipedia上的KNN词条中有一个比较经典的图如下:

从上图中我们可以看到,图中的有两个类型的样本数据,一类是蓝色的正方形,另一类是红色的三角形。而那个绿色的圆形是我们待分类的数据。
- 如果K=3,那么离绿色点最近的有2个红色三角形和1个蓝色的正方形,这3个点投票,于是绿色的这个待分类点属于红色的三角形。
- 如果K=5,那么离绿色点最近的有2个红色三角形和3个蓝色的正方形,这5个点投票,于是绿色的这个待分类点属于蓝色的正方形。
我们可以看到,机器学习的本质——是基于一种数据统计的方法!那么,这个算法有什么用呢?我们来看几个示例。
目录
产品质量判断
假设我们需要判断纸巾的品质好坏,纸巾的品质好坏可以抽像出两个向量,一个是“酸腐蚀的时间”,一个是“能承受的压强”。如果我们的样本空间如下:(所谓样本空间,又叫Training Data,也就是用于机器学习的数据)
|
向量X1 耐酸时间(秒) |
向量X2 圧强(公斤/平方米) |
品质Y |
|
7 |
7 |
坏 |
|
7 |
4 |
坏 |
|
3 |
4 |
好 |
|
1 |
4 |
好 |
那么,如果 X1 = 3 和 X2 = 7, 这个毛巾的品质是什么呢?这里就可以用到KNN算法来判断了。
假设K=3,K应该是一个奇数,这样可以保证不会有平票,下面是我们计算(3,7)到所有点的距离。(关于那些距离公式,可以参看K-Means算法中的距离公式)
|
向量X1 耐酸时间(秒) |
向量X2 圧强(公斤/平方米) |
计算到 (3, 7)的距离 |
向量Y |
|
7 |
7 |
|
坏 |
|
7 |
4 |
|
N/A |
|
3 |
4 |
|
好 |
|
1 |
4 |
|
好 |
所以,最后的投票,好的有2票,坏的有1票,最终需要测试的(3,7)是合格品。(当然,你还可以使用权重——可以把距离值做为权重,越近的权重越大,这样可能会更准确一些)
注:示例来自这里,K-NearestNeighbors Excel表格下载
预测
假设我们有下面一组数据,假设X是流逝的秒数,Y值是随时间变换的一个数值(你可以想像是股票值)

那么,当时间是6.5秒的时候,Y值会是多少呢?我们可以用KNN算法来预测之。
这里,让我们假设K=2,于是我们可以计算所有X点到6.5的距离,如:X=5.1,距离是 | 6.5 – 5.1 | = 1.4, X = 1.2 那么距离是 | 6.5 – 1.2 | = 5.3 。于是我们得到下面的表:

注意,上图中因为K=2,所以得到X=4 和 X =5.1的点最近,得到的Y的值分别为27和8,在这种情况下,我们可以简单的使用平均值来计算:![]()
于是,最终预测的数值为:17.5

注:示例来自这里,KNN_TimeSeries Excel表格下载
插值,平滑曲线
KNN算法还可以用来做平滑曲线用,这个用法比较另类。假如我们的样本数据如下(和上面的一样):
![]()
要平滑这些点,我们需要在其中插入一些值,比如我们用步长为0.1开始插值,从0到6开始,计算到所有X点的距离(绝对值),下图给出了从0到0.5 的数据:

下图给出了从2.5到3.5插入的11个值,然后计算他们到各个X的距离,假值K=4,那么我们就用最近4个X的Y值,然后求平均值,得到下面的表:

于是可以从0.0, 0.1, 0.2, 0.3 …. 1.1, 1.2, 1.3…..3.1, 3.2…..5.8, 5.9, 6.0 一个大表,跟据K的取值不同,得到下面的图:
 |
 |
 |
 |
 |
注:示例来自这里,KNN_Smoothing Excel表格下载
后记
最后,我想再多说两个事,
1) 一个是机器学习,算法基本上都比较简单,最难的是数学建模,把那些业务中的特性抽象成向量的过程,另一个是选取适合模型的数据样本。这两个事都不是简单的事。算法反而是比较简单的事。
2)对于KNN算法中找到离自己最近的K个点,是一个很经典的算法面试题,需要使用到的数据结构是“最大堆——Max Heap”,一种二叉树。你可以看看相关的算法。
(全文完)
(转载本站文章请注明作者和出处 酷 壳 – CoolShell ,请勿用于任何商业用途)





 (24 人打了分,平均分: 3.83 )
(24 人打了分,平均分: 3.83 )
《K Nearest Neighbor 算法》的相关评论
抢沙发,算法其实相当有趣
机器学习的本质——是基于一种数据统计的方法!
Basically, this sentence is quite inaccurate. Or I even can say, it is wrong. (from working desktop, no chinese input…)
请问股票预测哪里为什么K=2呢? 根据是什么? 在实际应用中如何得出这个值呢?我想肯定不是固定值啊,另外后面为什么只取了前两个最近的点(Y的值分别为27和8的哪两个点),为什么不是3个4个呢?这个和k=2 有关系?
人工智能和数据挖掘,很火的两个方向~
大根堆加KNN算法,很有意思。
万变不离其宗,数学确实是基础,建模。
其实如果仅仅是物理距离上的最近K个求解,用传统的KNN算法或者树来解决都有点太麻烦了.
其实有些机器学习算法还真不怎么简单= =比如HMM相关的算法
受教了。有个题外问题:为什么数据里,耐酸时间长,受压大却是差品质的毛巾?
真心感谢陈皓,我在这里学到了很多东西
同意,还有各种核方法、流形学习什么的,如果要做机器学习研究,往往需要掌握统计学、矩阵理论、最优化方法、随机过程、拓扑学其中的几种……
@Tony
评价一个事物好坏,首先要明确我们能用它来干什么,需要干什么。然后根据我们“认为”的这个事物的需要满足能力,来判断它的好坏。毛巾是用来擦我们身体部位的,那么这里我们的需要就是:能完成擦这个需要,并且使我们的”部位“感觉很舒服的东西,并且舒服的需要占据了很大的比重。结论就出来了,在一般的材料中,越硬,越不易磨损的东西,擦起来身体为很不舒服。所以。。
@dk
啊,多谢指点,我死脑筋了。
讲解的很详细,最近在研究脑肿瘤分割的算法,很受用,一直关注酷壳
其实从地理和空间科学的角度,KNN的较为经典方法是基于空间分割(空间索引)的算法,比如成熟的ANN算法
@Zitao
你的意思是站在概念性的角度,一定要用performance, task, training这样严格的定义?
不好意思,下面的图就真的理解不了怎么画出来。请原谅菜鸟,求解答。
@Tony
硬吧。。纤维的和棉的比就是压强大和更耐酸
算法菜鸟表示懂算法的都是大神
@陈皓 K的取值是怎么考量的呢?通篇貌似没提到哦
如果要做分類的話可以參考svm這個方法
這個方法非常神奇…
http://en.wikipedia.org/wiki/Support_vector_machine
程式的話在http://www.csie.ntu.edu.tw/~cjlin/libsvm/也有很多版本
一个kmean算法就敢说Machine learning简单,实在是让人觉得坐井观天,NN,DNN,HMM, CRF, BOOST, GMM, SVM每一个都需要极强的数学功底,纯engneer加以运用不过是车床工人罢了
先把engineer打对。。
非常同意,搞过学术的都知道这东西需要多少数学功底,当然了,什么都不懂也可以直接用,而且理解成简单@pengwang
受教了~~~最近在看KNN算法 打算编程实现,看来要把二项堆认真看看~~~
我记得KNN的高效实现是使用KD-Tree
学习了