性能测试应该怎么做?
 偶然间看到了阿里中间件Dubbo的性能测试报告,我觉得这份性能测试报告让人觉得做这性能测试的人根本不懂性能测试,我觉得这份报告会把大众带沟里去,所以,想写下这篇文章,做一点科普。
偶然间看到了阿里中间件Dubbo的性能测试报告,我觉得这份性能测试报告让人觉得做这性能测试的人根本不懂性能测试,我觉得这份报告会把大众带沟里去,所以,想写下这篇文章,做一点科普。
首先,这份测试报告里的主要问题如下:
1)用的全是平均值。老实说,平均值是非常不靠谱的。
2)响应时间没有和吞吐量TPS/QPS挂钩。而只是测试了低速率的情况,这是完全错误的。
3)响应时间和吞吐量没有和成功率挂钩。
目录
为什么平均值不靠谱
关于平均值为什么不靠谱,我相信大家读新闻的时候经常可以看到,平均工资,平均房价,平均支出,等等这样的字眼,你就知道为什么平均值不靠谱了。(这些都是数学游戏,对于理工科的同学来说,天生应该有免疫力)
软件的性能测试也一样,平均数也是不靠谱的,这里可以参看这篇详细的文章《Why Averages Suck and Percentiles are Great》,我在这里简单说一下。
我们知道,性能测试时,测试得到的结果数据不总是一样的,而是有高有低的,如果算平均值就会出现这样的情况,假如,测试了10次,有9次是1ms,而有1次是1s,那么平均数据就是100ms,很明显,这完全不能反应性能测试的情况,也许那1s的请求就是一个不正常的值,是个噪点,应该去掉。所以,我们会在一些评委打分中看到要去掉一个最高分一个最低分,然后再算平均值。
另外,中位数(Mean)可能会比平均数要稍微靠谱一些,所谓中位数的意就是把将一组数据按大小顺序排列,处在最中间位置的一个数叫做这组数据的中位数 ,这意味着至少有50%的数据低于或高于这个中位数。
当然,最为正确的统计做法是用百分比分布统计。也就是英文中的TP – Top Percentile ,TP50的意思在,50%的请求都小于某个值,TP90表示90%的请求小于某个时间。
比如:我们有一组数据:[ 10ms, 1s, 200ms, 100ms],我们把其从小到大排个序:[10ms, 100ms, 200ms, 1s],于是我们知道,TP50,就是50%的请求ceil(4*0.5)=2时间是小于100ms的,TP90就是90%的请求ceil(4*0.9)=4时间小于1s。于是:TP50就是100ms,TP90就是1s。
我以前在路透做的金融系统响应时间的性能测试的要求是这样的,99.9%的请求必须小于1ms,所有的平均时间必须小于1ms。两个条件的限制。
为什么响应时间(latency)要和吞吐量(Thoughput)挂钩
系统的性能如果只看吞吐量,不看响应时间是没有意义的。我的系统可以顶10万请求,但是响应时间已经到了5秒钟,这样的系统已经不可用了,这样的吞吐量也是没有意义的。
我们知道,当并发量(吞吐量)上涨的时候,系统会变得越来越不稳定,响应时间的波动也会越来越大,响应时间也会变得越来越慢,而吞吐率也越来越上不去(如下图所示),包括CPU的使用率情况也会如此。所以,当系统变得不稳定的时候,吞吐量已经没有意义了。吞吐量有意义的时候仅当系统稳定的时候。
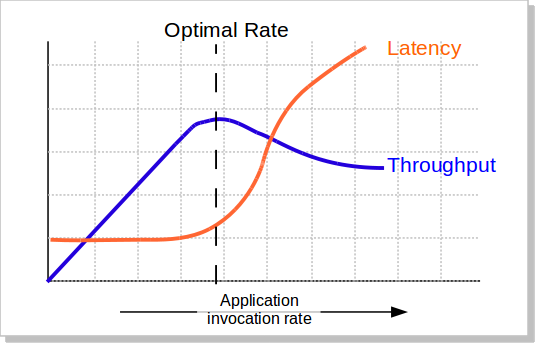
所以,吞吐量的值必需有响应时间来卡。比如:TP99小于100ms的时候,系统可以承载的最大并发数是1000qps。这意味着,我们要不断的在不同的并发数上测试,以找到软件的最稳定时的最大吞吐量。
为什么响应时间吞吐量和成功率要挂钩
我们这应该不难理解了,如果请求不成功的话,都还做毛的性能测试。比如,我说我的系统并发可以达到10万,但是失败率是
40%,那么,这10万的并发完全就是一个笑话了。
性能测试的失败率的容忍应该是非常低的。对于一些关键系统,成功请求数必须在100%,一点都不能含糊。
如何严谨地做性能测试
一般来说,性能测试要统一考虑这么几个因素:Thoughput吞吐量,Latency响应时间,资源利用(CPU/MEM/IO/Bandwidth…),成功率,系统稳定性。
下面的这些性能测试的方式基本上来源自我的老老东家汤森路透,一家做real-time的金融数据系统的公司。
一,你得定义一个系统的响应时间latency,建议是TP99,以及成功率。比如路透的定义:99.9%的响应时间必需在1ms之内,平均响应时间在1ms以内,100%的请求成功。
二,在这个响应时间的限制下,找到最高的吞吐量。测试用的数据,需要有大中小各种尺寸的数据,并可以混合。最好使用生产线上的测试数据。
三,在这个吞吐量做Soak Test,比如:使用第二步测试得到的吞吐量连续7天的不间断的压测系统。然后收集CPU,内存,硬盘/网络IO,等指标,查看系统是否稳定,比如,CPU是平稳的,内存使用也是平稳的。那么,这个值就是系统的性能
四,找到系统的极限值。比如:在成功率100%的情况下(不考虑响应时间的长短),系统能坚持10分钟的吞吐量。
五,做Burst Test。用第二步得到的吞吐量执行5分钟,然后在第四步得到的极限值执行1分钟,再回到第二步的吞吐量执行5钟,再到第四步的权限值执行1分钟,如此往复个一段时间,比如2天。收集系统数据:CPU、内存、硬盘/网络IO等,观察他们的曲线,以及相应的响应时间,确保系统是稳定的。
六、低吞吐量和网络小包的测试。有时候,在低吞吐量的时候,可能会导致latency上升,比如TCP_NODELAY的参数没有开启会导致latency上升(详见TCP的那些事),而网络小包会导致带宽用不满也会导致性能上不去,所以,性能测试还需要根据实际情况有选择的测试一下这两咱场景。
(注:在路透,路透会用第二步得到的吞吐量乘以66.7%来做为系统的软报警线,80%做为系统的硬报警线,而极限值仅仅用来扛突发的peak)
是不是很繁锁?是的,只因为,这是工程,工程是一门科学,科学是严谨的。
欢迎大家也分享一下你们性能测试的经验和方法。
(全文完)
(转载本站文章请注明作者和出处 酷 壳 – CoolShell ,请勿用于任何商业用途)




 (74 人打了分,平均分: 4.54 )
(74 人打了分,平均分: 4.54 )
《性能测试应该怎么做?》的相关评论
Mean -> Median,捡个漏
谢谢,已修正
阿里这也太坑人了吧,连概念都混淆。
只是突出了重点吧,默认可能是成功率在99%呗。如果要寻根究底,给的结果确实是不够严谨的
为什么响应时间(latency)要和吞吐量(Throughput)挂钩
这里应该是Throughput吧
@Puriney
mean有中位数平均值的意思
— 114.114.114.114 ping statistics —
1 packets transmitted, 1 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 31.302/31.302/31.302/0.000 ms
这是ping的输出。哪个报告里的作者不会连ping的输出都没注意到吧?
@Puriney
Requests per second: 806.18 [#/sec] (mean)
Time per request: 2480.835 [ms] (mean)
Time per request: 1.240 [ms] (mean, across all concurrent requests)
就是mean 亲爱的
我这边是关注, 成功失败率,每秒的处理数,单个响应时间 ,每个时间区间的请求统计 .
不同控制标准的制定也是一项经验工作,比如如何预估期望的吞吐量、成功率、并发数等问题,不知道耗子叔方便稍微谈一下吗? 还是说通过已有的类似数据通过一个概率模型换算的? 谢谢
“`
> c sort(c)
[1] 18 20 36 38 48 69 72 75 86 94 99
> mean(c)
[1] 59.54545
> median(c)
[1] 69
“`
作为一个RD最近在帮助QA做性能测试,我们采用一套备用的集群做测试,测试数据来源于线上的真实数据,然后在不同的QPS下重放这些请求(感觉人工大量构造,小中大三中规模的请求,不可行)利用的工具是Jmeter和公司内部的测试平台,统计响应的平响,各分位平响,还有成功率等指标。不过在找极限值上很难做,单机的极限可能还好,集群的极限可能需要多台机器的超高并发才能实现了。另外文章提到的观察一两天后看效果,这种对于大系统整体性能测试可以接受,但是对于小系统来说有点儿太长了吧。
文字校错,是繁琐而不是烦锁
谢谢!已更正
mean 是均值,median 才是中位数。
@dy
有出处吗?据我所知没有这个意思,我查了维基百科也没看见。
The “mean” is the “average” you’re used to, where you add up all the numbers and then divide by the number of numbers. The “median” is the “middle” value in the list of numbers. To find the median, your numbers have to be listed in numerical order, so you may have to rewrite your list first.
LZ说的应该是Median
我也进行过一些性能测试,但是进行的次数越多,就越迷糊:到底该怎么进行性能测试?(我的性能测试,都是我自己想象中的性能测试,自己开发、自己测试;并不是专业的调理)
终于看到耗子大哥这文章了,真的是非常需要。
有个疑问:耗子大哥提到了5步;3,4,5都提了测试量(时间长度);但是,1和2没有提。是不是也需要一个测试量,比如说多少时间?比如说测试多少数据?
@峰云就她了
你猜我是谁
在web应用中,吞吐量这个概念是会细分为并发数(跟用户数正相关)和QPS的,在限制latency 都是 1ms 的情况下,并发100 时的QPS和200时的是不一样的,这样我们说系统的承载能力有多大的时候,就要描述两个变量:在并发为n的情况下QPS为m是否可用。这时候测试画出来的图应该是三维的(latency concurrency QPS),表现是一个面,再限制latency=1ms,该面在此限制之下的部分为可用临界,其在QPS-concurreny平面的投影,才是系统可用数据。
具体做法就是 测各个并发下响应延迟在1ms下的最大QPS,然后以横轴为并发数,纵轴为QPS,画图,曲线和坐标轴围城的区域就是可用区域(这个区域其实就是上面三维图像的投影)
可是不知为啥很少看到有人这样压测。
现在有浩兄这样负责任, 有水平的, 已经找不出几人了
请问性格测试应该怎么做呢?;)
@Justfly
因为很多测试的工作无非就是:这点点,那点点。
请问一下关于吞吐量的定义,吞吐量是否等价于并发量,例如50个并发来压http服务器每秒能压出上千的响应,那么吞吐量还是50吗?还有,假如不单单只是一个http请求,而是多个http请求组成的一个完整流程,其中有的协议响应快有的慢,50个并发,每秒只能跑完200个流程,那么哪个才能被定义为吞吐量?
Thoughput -> Throughput
@石樱灯笼
恐怕“这点点,那点点”也需要学问吧,那开发是不是也能简单总结成“这抄抄,那抄抄”?
这位仁兄回答的精彩,手工测试对用例的设计也不是那么简单,没有那么多积累,又怎么来的自动化测试
正解。
正文里的“最大并发数是1000qps” —— 这样写不严谨吧
个人理解,按照上下文的说法,qps应该是对应系统的吞吐量指标比较合适。
关于第四条,越看越懵
很想问下,系统的极限值是指什么,最大并发数,最高吞吐量,还是服务器CPU等各项指标??超出极限值的表现是指开始出现报错吗??
然后如何找到系统极限值呢?虽然有给个例子,还是看不懂,“坚持10分钟的吞吐量”这个吞吐量是第二步获取到的吞吐量吗??可是第三步已经有在这个吞吐量的基础上做测试,应该也一并测试过了才对,那是最大并发数情况下的吞吐量或者其他??
总之现在一脸懵逼,还望普及下
@石樱灯笼
说点点是没有错,不点怎么测试呢?就像写代码,这里抄抄,哪里引用一下一个道理。但是这就不需要技术了么?不见得吧!
t
z
好
性能测试和压力测试有哪些区别呢?
性能测试的定义是:
When you want to check your website performance and app performance, as well as servers, databases, networks, etc. If you work with the waterfall methodology, then at least each time you release a version. If you’re shifting left and going agile, you should test continuously.
压力测试的定义是:
Load testing is testing that checks how systems function under a heavy number of concurrent virtual users performing transactions over a certain period of time. Or in other words, how systems handle heavy load volumes. There are a few types of open-source load testing tools, with JMeter being the most popular one.
文章里有点错误:系统可以承载的最大并发数是1000qps
并发和qps可不一样,不是一种东西
对于我这种新手来说讲的非常的清晰,顶耗子哥~
看了coolshell几年了,以前有很多看不懂,现在终于可以看懂大部分文章了。以前看不懂的时候,看到很多高深的心里感觉很怵,现在好多了,能看懂之后反倒感觉有点喜欢看了。
恩, 我是2017年刚刚关注浩哥博客的,决定永久关注了!
工程是一门科学,科学是严谨的,态度赞一个
吞吐量的英文是 throughput 文章里漏了一个r :)
学习了,赞一个!
我觉得其实也是告诉大家不要盲从大公司技术,学习大公司的技术长处,简化到可以满足自身业务,不一定必须使用大公司技术工具,有时候过于盲从技术反而使生产效率低下。
请问,通常用那些压测工具?
ab , jmeter,这些工具压出来,有时候出入挺大的。