多版本并发控制(MVCC)在分布式系统中的应用
【感谢 Todd投递本文 – 微博帐号:weidagang 】
目录
问题
最近项目中遇到了一个分布式系统的并发控制问题。该问题可以抽象为:某分布式系统由一个数据中心D和若干业务处理中心L1,L2 … Ln组成;D本质上是一个key-value存储,它对外提供基于HTTP协议的CRUD操作接口。L的业务逻辑可以抽象为下面3个步骤:
- read: 根据keySet {k1, … kn}从D获取keyValueSet {k1:v1, … kn:vn}
- do: 根据keyValueSet进行业务处理,得到需要更新的数据集keyValueSet’ {k1′:v1′, … km’:vm’} (注:读取的keySet和更新的keySet’可能不同)
- update: 把keyValueSet’更新到D (注:D保证在一次调用更新多个key的原子性)
在没有事务支持的情况下,多个L进行并发处理可能会导致数据一致性问题。比如,考虑L1和L2的如下执行顺序:
- L1从D读取key:123对应的值100
- L2从D读取key:123对应的100
- L1将key:123更新为100 + 1
- L2将key:123更新为100 + 2
如果L1和L2串行执行,key:123对应的值将为103,但上面并发执行中L1的执行效果完全被L2所覆盖,实际key:123所对应的值变成了102。
解决方案1:基于锁的事务
为了让L的处理具有可串行化特性(Serializability),一种最直接的解决方案就是考虑为D加上基于锁的简单事务。让L在进行业务处理前先锁定D,完成以后释放锁。另外,为了防止持有锁的L由于某种原因长时间未提交事务,D还需要具有超时机制,当L尝试提交一个已超时的事务时会得到一个错误响应。

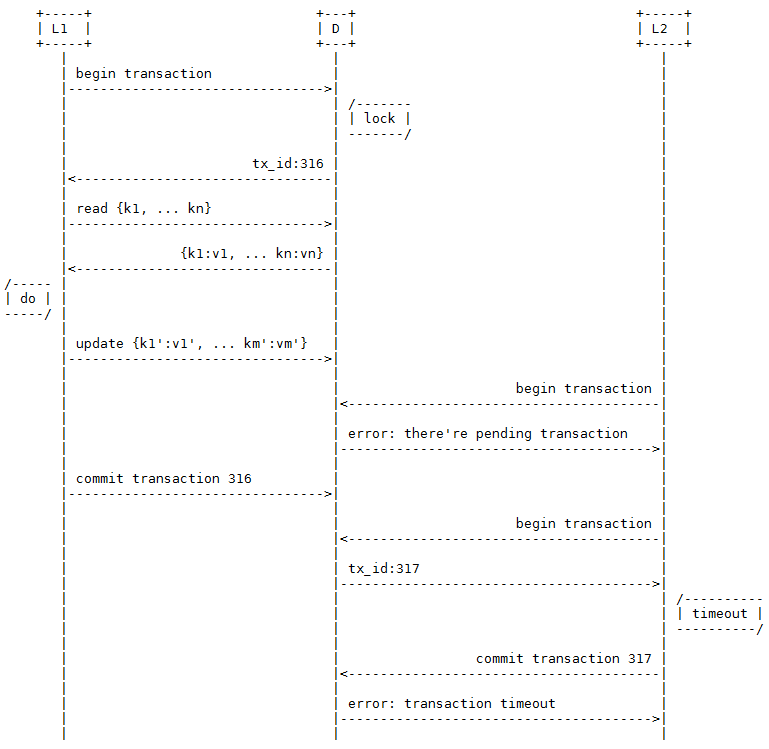
本方案的优点是实现简单,缺点是锁定了整个数据集,粒度太大;时间上包含了L的整个处理时间,跨度太长。虽然我们可以考虑把锁定粒度降低到数据项级别,按key进行锁定,但这又会带来其他的问题。由于更新的keySet’可能是事先不确定的,所以可能无法在开始事务时锁定所有的key;如果分阶段来锁定需要的key,又可能出现死锁(Deadlock)问题。另外,按key锁定在有锁争用的情况下并不能解决锁定时间太长的问题。所以,按key锁定仍然存在重要的不足之处。
解决方案2:多版本并发控制
为了实现可串行化,同时避免锁机制存在的各种问题,我们可以采用基于多版本并发控制(Multiversion concurrency control,MVCC)思想的无锁事务机制。人们一般把基于锁的并发控制机制称成为悲观机制,而把MVCC机制称为乐观机制。这是因为锁机制是一种预防性的,读会阻塞写,写也会阻塞读,当锁定粒度较大,时间较长时并发性能就不会太好;而MVCC是一种后验性的,读不阻塞写,写也不阻塞读,等到提交的时候才检验是否有冲突,由于没有锁,所以读写不会相互阻塞,从而大大提升了并发性能。我们可以借用源代码版本控制来理解MVCC,每个人都可以自由地阅读和修改本地的代码,相互之间不会阻塞,只在提交的时候版本控制器会检查冲突,并提示merge。目前,Oracle、PostgreSQL和MySQL都已支持基于MVCC的并发机制,但具体实现各有不同。
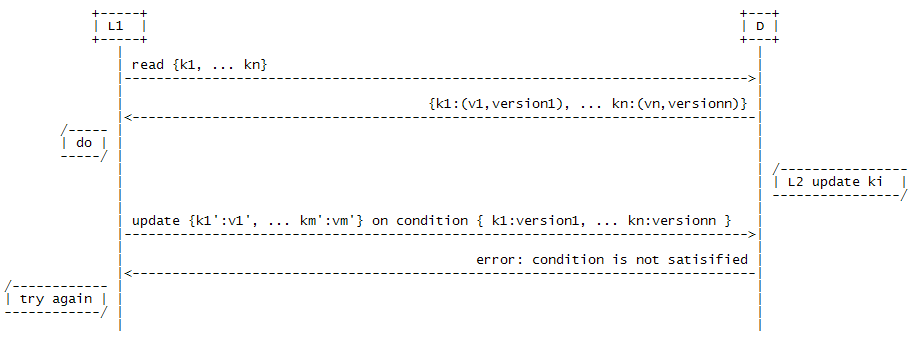
MVCC的一种简单实现是基于CAS(Compare-and-swap)思想的有条件更新(Conditional Update)。普通的update参数只包含了一个keyValueSet’,Conditional Update在此基础上加上了一组更新条件conditionSet { … data[keyx]=valuex, … },即只有在D满足更新条件的情况下才将数据更新为keyValueSet’;否则,返回错误信息。这样,L就形成了如下图所示的Try/Conditional Update/(Try again)的处理模式:


虽然对单个L来讲不能保证每次都成功更新,但从整个系统来看,总是有任务能够顺利进行。这种方案利用Conditional Update避免了大粒度和长时间的锁定,当各个业务之间资源争用不大的情况下,并发性能很好。不过,由于Conditional Update需要更多的参数,如果condition中value的长度很长,那么每次网络传送的数据量就会比较大,从而导致性能下降。特别是当需要更新的keyValueSet’很小,而condition很大时,就显得非常不经济。
为了避免condition太大所带来的性能问题,可以为每条数据项增加一个int型的版本号字段,由D维护该版本号,每次数据有更新就增加版本号;L在进行Conditional Update时,通过版本号取代具体的值。

另一个问题是上面的解决方案假设了D是可以支持Conditional Update的;那么,如果D是一个不支持Conditional Update的第三方的key-value存储怎么办呢?这时,我们可以在L和D之间增加一个P作为代理,所有的CRUD操作都必须经过P,让P来进行条件检查,而实际的数据操作放在D。这种方式实现了条件检查和数据操作的分离,但同时降低了性能,需要在P中增加cache,提升性能。由于P是D的唯一客户端;所以,P的cache管理是非常简单的,不必像多客户端情形担心缓存的失效。不过,实际上,据我所知redis和Amazon SimpleDB都已经有了Conditional Update的支持。
悲观锁和MVCC对比
上面介绍了悲观锁和MVCC的基本原理,但是对于它们分别适用于什么场合,不同的场合下两种机制优劣具体表现在什么地方还不是很清楚。这里我就对一些典型的应用场景进行简单的分析。需要注意的是下面的分析不针对分布式,悲观锁和MVCC两种机制在分布式系统、单数据库系统、甚至到内存变量各个层次都存在。
### 场景1:对读的响应速度要求高
有一类系统更新特别频繁,并且对读的响应速度要求很高,如股票交易系统。在悲观锁机制下,写会阻塞读,那么当有写操作时,读操作的响应速度就会受到影响;而MVCC不存在读写锁,读操作是不受任何阻塞的,所以读的响应速度会更快更稳定。
### 场景2:读远多于写
对于许多系统来讲,读操作的比例往往远大于写操作,特别是某些海量并发读的系统。在悲观锁机制下,当有写操作占用锁,就会有大量的读操作被阻塞,影响并发性能;而MVCC可以保持比较高且稳定的读并发能力。
### 场景3:写操作冲突频繁
如果系统中写操作的比例很高,且冲突频繁,这时就需要仔细评估。假设两个有冲突的业务L1和L2,它们在单独执行是分别耗时t1,t2。在悲观锁机制下,它们的总时间大约等于串行执行的时间:
T = t1 + t2
而在MVCC下,假设L1在L2之前更新,L2需要retry一次,它们的总时间大约等于L2执行两次的时间(这里假设L2的两次执行耗时相等,更好的情况是,如果第1次能缓存下部分有效结果,第二次执行L2耗时是可能减小的):
T’ = 2 * t2
这时关键是要评估retry的代价,如果retry的代价很低,比如,对某个计数器递增,又或者第二次执行可以比第一次快很多,这时采用MVCC机制就比较适合。反之,如果retry的代价很大,比如,报表统计运算需要算几小时甚至一天那就应该采用锁机制避免retry。
从上面的分析,我们可以简单的得出这样的结论:对读的响应速度和并发性要求比较高的场景适合MVCC;而retry代价越大的场景越适合悲观锁机制。
总结
本文介绍了一种基于多版本并发控制(MVCC)思想的Conditional Update解决分布式系统并发控制问题的方法。和基于悲观锁的方法相比,该方法避免了大粒度和长时间的锁定,能更好地适应对读的响应速度和并发性要求高的场景。
参考
- Wikipedia – Serializability
- Wikipedia – Compare-and-swap
- Wikipedia – Multiversion concurrency control
- Lock-free algorithms: The try/commit/(try again) pattern
- Amazon SimpleDB FAQs – Does Amazon SimpleDB support transactions?
- redis – Transactions
- A Quick Survey of MultiVersion Concurrency Algorithms
- 非阻塞算法思想在关系数据库应用程序开发中的使用
友情推荐
本文的图是用我自己开发的TextDiagram工具画的,欢迎试用!如果您喜欢,请推荐给朋友,谢谢!
(转载本站文章请注明作者和出处 酷 壳 – CoolShell ,请勿用于任何商业用途)






 (26 人打了分,平均分: 3.46 )
(26 人打了分,平均分: 3.46 )
《多版本并发控制(MVCC)在分布式系统中的应用》的相关评论
TextDiagram真不错~~ 学习了~~
Rails 的 ActiveRecord 提供了 OptimisticLocking,是在应用的级别实现类似的效果(当然要在数据表里增加 lock_version INT 字段),发生冲突的时候 ActiveRecord 会抛出 StaleObjectError。
这里有几个问题:
0. 发生冲突的时候你们是怎么处理的呢?Retry, or fail fast?
1. 这种 conditional update 在数据发生冲突的时候,会执行 ROLLBACK,还是直接忽略此次操作(完全不影响数据)?
2. 如果执行 ROLLBACK,那就是说这个操作本身也在 transaction 中咯?
@iwinux
0. retry
1. ignore
感觉构架比较复杂,不断的Try again,耗掉太多的带宽。而且不一定什么时候可以保证事务的最终完成。当然这要实际的场景和数据来说明。另外,如果是分布式kv系统的话,完全可以使用LSM+AOF来提升并发性能
Hi 想请教下你的图是用什么工具画得?
基本上主流的nosql数据库都可以支持cas更新,只要限制一下try again的次数就好。
@Leon
http://textdiagram.sinaapp.com/
学习咯,不晓得有没有简单的范例呢?新手……
学习了哈
我有个想法,如果我们把所有的写操作,都放在一个队列Q里,然后Q挨个儿顺序执行写入操作,这样是不是就能避免锁的问题?
针对同一个键,我们还可以进行操作合并,这样总体效率会更高些。
如果Q足够大的话,每次写入都可以立刻返回,不存在超时但可能延迟更新。反之,把Q设的小一点,则更新就比较及时,但写入就有可能失败。
@abadcafe
>我有个想法,如果我们把所有的写操作,都放在一个队列Q里,然后Q挨个儿顺序执行写入操作,这样是不是就能避免锁的问题?
这种思路不能解决一致性问题,因为如果L的决策是基于过时的数据(读取后被其他人更新),那么这个决策结果是不应该被更新到D的。换句话说,上面的思路并不能防止基于过时数据产生的结果被更新到D,这正是锁机制和MVCC所解决的问题。
@Todd
如果要求一致性的话,那把队列Q改为cache C,读写都从cache里走。cache里的每一项,都可以用atomic + while(1),或者用spinlock,来进行保护,这样是不是会好些?
有趣~Clojure语言在处理并发的方法STM(Software transactional memory)也是以MVCC为基础的。
它的创造者说STM的效率在四核或更少的机器上要低于基于锁的并发方案,由于要提前log读写操作和提交写操作时检查冲突。
乐观锁也有问题,我觉得尤其不合适在一些需要用户大量更新的地方,比如编辑器。因为此种情况下一旦乐观锁发现有冲突,会导致很难处理用户已有编辑数据的问题。丢失用户的数据还是让用户手动merge?
乐观锁处理问题代价很轻,却带来了不好的客户体验。所以比较好的方式是结合乐观锁和悲观锁。在得知已经有人锁定的情况下通知前段用户,比如只显示一个只读页面,从而避免用户大量的操作被迫无效的尴尬。
这个真心没看懂。。。
这不就是free lock的分布式版本……
在微博上看到了一下 不过真的看不懂啊
顺便问下 文章结尾处的图片是怎么弄的?
谢谢
怒赞TextDiagram,找这样的工具很久了。鄙视自己,就是懒不愿意自己写一个
当MVCC的提交冲突时,可以用以太网类似的机制,减少retry 的次数.
每次提交,如果失败返回一个失败的状态,再加一个下次提交的最小间隔时间. 数据中心或者其对应的代理可以根据系统当前资源的使用状态可以返回这样一个数值. 客户根据这个值,来确定下次提交时间.这样可以减少retry 的次数,同时也可以减少带卡的占用.
系统返回最小间隔时间,可以根据事务分类(典型的事务的最小时间)以及当前需要更新的队列数量,以及历史数据来给出一个值.这个值也可以在实际的应用中自行调整.
@roc
>>再加一个下次提交的最小间隔时间
这个在MVCC中似乎不适用,因为D并没有被*占用*,只有当资源被占用时,估计一个释放时间才是有效的。否则,应该是立刻retry。
@Todd
有点不太明白,或许是缺少上下文理解错了.
提交失败的原因是什么? 不是资源被占用,而是条件没有满足.
但是retry 就可以提交了,为什么? 难道 是retry提交时,重新修改条件吗,还是系统状态变了而满足条件了?
自己做 技术工具 1
好像SVN也采用了与MVCC类似的技术!
@roc 赞,这个建议很不错!对于非internet的应用,给一个建议时间是减少无谓retry的很好的机制,而对于有internet的应用(比如现在流程的RESTAPI机制)这个建议时间一般就很难给了,因为一个request在internet上耗费的时间与在网络内部耗费的时间比带有很大的不确定性,从而想给一个靠谱的时间就比较困难。
@roc
我觉得你们说了两个场景,跟业务逻辑对数据的访问scope直接相关:
1. 如果业务逻辑一般都是访问很少的数据,比如都访问某个Key-Value,那么应该立刻重试,因为当commit检测到失败的时候就意味着该Key-Value已经被释放了(有人修改了Key-Value并已修改完毕),这样效率才高。
2. 如果业务逻辑一般都访问很多数据,比如业务L1访问KKey1, Key2, Key3, Key4,而业务L2访问Key4, Key6, Key2, Key1,如果L2commit的时候发现Key2的update condition失败,这时候如果立刻重试的话,L2可能还要承担Key4的update condition失败的问题(因为L1在持续的更新Key2, Key3, Key4),这种case等待一会再重试就好一点。
我也只是按照自己的理解,欢迎探讨。
MVCC方法在处理数据的时候是怎样同步的?
如果版本不一致,在真正开始处理数据时就能够停下来保证安全,但问题是,如果两个并发请求携带的版本号是一样的,那么服务端在处理这些请求的时候应该也是串行的吧。
@Nelson
是的,服务器端要保证并发事务请求是可串行化(serializable)的。可串行化的意思是事务的并发执行效果等同于它们串行执行的效果。需要注意的是服务器端实现可串行化的方法同样有两种:MVCC和锁。也就是说,MVCC在各个层次都存在,从宏观的分布式,到单机事务处理,到微观的内存变量都有这两种分别。在最微观的层次,MVCC是通过CPU的CAS原语来支持的,比如,某些语言中多线程更新或读取一个int型变量不需要加锁,就是通过CAS原语来实现的。
这种方式实际上跟CAS(Compare And Swap)就是一回事吧。
“在L和D之间增加一个P作为代理,所有的CRUD操作都必须经过P,让P来进行条件检查,而实际的数据操作放在D。这种方式实现了条件检查和数据操作的分离,但同时降低了性能,需要在P中增加cache,提升性能。由于P是D的唯一客户端;所以,P的cache管理是非常简单的,不必像多客户端情形担心缓存的失效。”
1 不会出现这种情况吗?
a:L发送更新操作命令,条件当数据版本为1.0
b:L发送更新操作命令,条件为数据版本为1.0
a:P检查更新条件,条件符合
b:P检查更新条件,条件符合
a:D更新,数据版本变为1.1
b:D更新,但当前数据版本变为了1.1,按要求不应该更新,但这里做了更新操作
这样不是还是存在锁的问题吗?
2 需要在P中增加cache,提升性能:缓存是有延时的,这不是同时又造成了无法实现多版本控制?缓存在这里真的有用吗?
这种场景应该把应用层部署到数据源那里.或者应用层缓存,或者批处理.频繁开连接检查锁,分布式大忌.
而且死锁也有算法的.