TCP 的那些事儿(下)
 这篇文章是下篇,所以如果你对TCP不熟悉的话,还请你先看看上篇《TCP的那些事儿(上)》 上篇中,我们介绍了TCP的协议头、状态机、数据重传中的东西。但是TCP要解决一个很大的事,那就是要在一个网络根据不同的情况来动态调整自己的发包的速度,小则让自己的连接更稳定,大则让整个网络更稳定。在你阅读下篇之前,你需要做好准备,本篇文章有好些算法和策略,可能会引发你的各种思考,让你的大脑分配很多内存和计算资源,所以,不适合在厕所中阅读。
这篇文章是下篇,所以如果你对TCP不熟悉的话,还请你先看看上篇《TCP的那些事儿(上)》 上篇中,我们介绍了TCP的协议头、状态机、数据重传中的东西。但是TCP要解决一个很大的事,那就是要在一个网络根据不同的情况来动态调整自己的发包的速度,小则让自己的连接更稳定,大则让整个网络更稳定。在你阅读下篇之前,你需要做好准备,本篇文章有好些算法和策略,可能会引发你的各种思考,让你的大脑分配很多内存和计算资源,所以,不适合在厕所中阅读。
目录
TCP的RTT算法
从前面的TCP重传机制我们知道Timeout的设置对于重传非常重要。
- 设长了,重发就慢,丢了老半天才重发,没有效率,性能差;
- 设短了,会导致可能并没有丢就重发。于是重发的就快,会增加网络拥塞,导致更多的超时,更多的超时导致更多的重发。
而且,这个超时时间在不同的网络的情况下,根本没有办法设置一个死的值。只能动态地设置。 为了动态地设置,TCP引入了RTT——Round Trip Time,也就是一个数据包从发出去到回来的时间。这样发送端就大约知道需要多少的时间,从而可以方便地设置Timeout——RTO(Retransmission TimeOut),以让我们的重传机制更高效。 听起来似乎很简单,好像就是在发送端发包时记下t0,然后接收端再把这个ack回来时再记一个t1,于是RTT = t1 – t0。没那么简单,这只是一个采样,不能代表普遍情况。
经典算法
RFC793 中定义的经典算法是这样的:
1)首先,先采样RTT,记下最近好几次的RTT值。
2)然后做平滑计算SRTT( Smoothed RTT)。公式为:(其中的 α 取值在0.8 到 0.9之间,这个算法英文叫Exponential weighted moving average,中文叫:加权移动平均)
SRTT = ( α * SRTT ) + ((1- α) * RTT)
3)开始计算RTO。公式如下:
RTO = min [ UBOUND, max [ LBOUND, (β * SRTT) ] ]
其中:
- UBOUND是最大的timeout时间,上限值
- LBOUND是最小的timeout时间,下限值
- β 值一般在1.3到2.0之间。
Karn / Partridge 算法
但是上面的这个算法在重传的时候会出有一个终极问题——你是用第一次发数据的时间和ack回来的时间做RTT样本值,还是用重传的时间和ACK回来的时间做RTT样本值?
这个问题无论你选那头都是按下葫芦起了瓢。 如下图所示:
- 情况(a)是ack没回来,所以重传。如果你计算第一次发送和ACK的时间,那么,明显算大了。
- 情况(b)是ack回来慢了,但是导致了重传,但刚重传不一会儿,之前ACK就回来了。如果你是算重传的时间和ACK回来的时间的差,就会算短了。
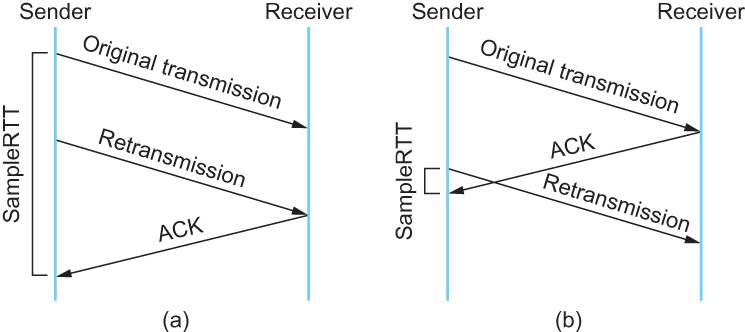
所以1987年的时候,搞了一个叫Karn / Partridge Algorithm,这个算法的最大特点是——忽略重传,不把重传的RTT做采样(你看,你不需要去解决不存在的问题)。
但是,这样一来,又会引发一个大BUG——如果在某一时间,网络闪动,突然变慢了,产生了比较大的延时,这个延时导致要重转所有的包(因为之前的RTO很小),于是,因为重转的不算,所以,RTO就不会被更新,这是一个灾难。 于是Karn算法用了一个取巧的方式——只要一发生重传,就对现有的RTO值翻倍(这就是所谓的 Exponential backoff),很明显,这种死规矩对于一个需要估计比较准确的RTT也不靠谱。
Jacobson / Karels 算法
前面两种算法用的都是“加权移动平均”,这种方法最大的毛病就是如果RTT有一个大的波动的话,很难被发现,因为被平滑掉了。所以,1988年,又有人推出来了一个新的算法,这个算法叫Jacobson / Karels Algorithm(参看RFC6289)。这个算法引入了最新的RTT的采样和平滑过的SRTT的差距做因子来计算。 公式如下:(其中的DevRTT是Deviation RTT的意思)
SRTT = SRTT + α (RTT – SRTT) —— 计算平滑RTT
DevRTT = (1-β)*DevRTT + β*(|RTT-SRTT|) ——计算平滑RTT和真实的差距(加权移动平均)
RTO= µ * SRTT + ∂ *DevRTT —— 神一样的公式
(其中:在Linux下,α = 0.125,β = 0.25, μ = 1,∂ = 4 ——这就是算法中的“调得一手好参数”,nobody knows why, it just works…) 最后的这个算法在被用在今天的TCP协议中(Linux的源代码在:tcp_rtt_estimator)。
TCP滑动窗口
需要说明一下,如果你不了解TCP的滑动窗口这个事,你等于不了解TCP协议。我们都知道,TCP必需要解决的可靠传输以及包乱序(reordering)的问题,所以,TCP必需要知道网络实际的数据处理带宽或是数据处理速度,这样才不会引起网络拥塞,导致丢包。
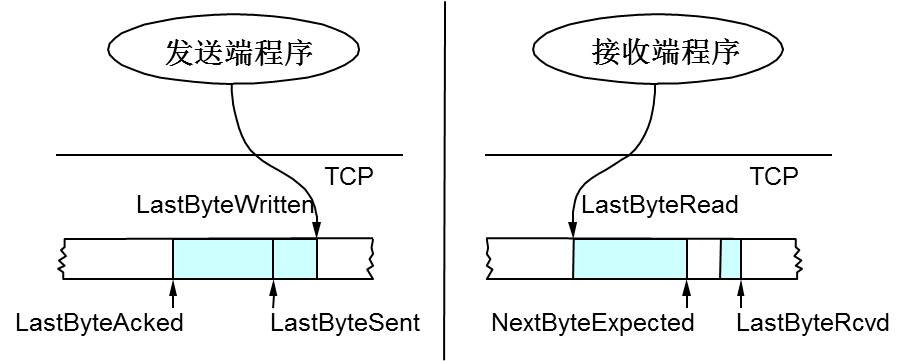
所以,TCP引入了一些技术和设计来做网络流控,Sliding Window是其中一个技术。 前面我们说过,TCP头里有一个字段叫Window,又叫Advertised-Window,这个字段是接收端告诉发送端自己还有多少缓冲区可以接收数据。于是发送端就可以根据这个接收端的处理能力来发送数据,而不会导致接收端处理不过来。 为了说明滑动窗口,我们需要先看一下TCP缓冲区的一些数据结构: