浏览器的渲染原理简介
看到这个标题大家一定会想到这篇神文《How Browsers Work》,这篇文章把浏览器的很多细节讲得很细,而且也被翻译成了中文。为什么我还想写一篇呢?因为两个原因,
1)这篇文章太长了,阅读成本太大,不能一口气读完。
2)花了大力气读了这篇文章后可以了解很多,但似乎对工作没什么帮助。
所以,我准备写下这篇文章来解决上述两个问题。希望你能在上班途中,或是坐马桶时就能读完,并能从中学会一些能用在工作上的东西。
目录
浏览器工作大流程
废话少说,先来看个图:
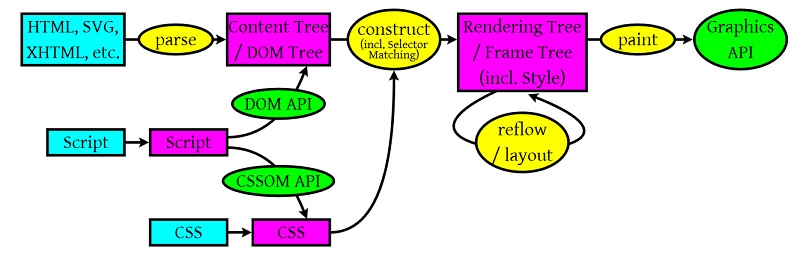
从上面这个图中,我们可以看到那么几个事:
1)浏览器会解析三个东西:
- 一个是HTML/SVG/XHTML,事实上,Webkit有三个C++的类对应这三类文档。解析这三种文件会产生一个DOM Tree。
- CSS,解析CSS会产生CSS规则树。
- Javascript,脚本,主要是通过DOM API和CSSOM API来操作DOM Tree和CSS Rule Tree.
2)解析完成后,浏览器引擎会通过DOM Tree 和 CSS Rule Tree 来构造 Rendering Tree。注意:
- Rendering Tree 渲染树并不等同于DOM树,因为一些像Header或display:none的东西就没必要放在渲染树中了。
- CSS 的 Rule Tree主要是为了完成匹配并把CSS Rule附加上Rendering Tree上的每个Element。也就是DOM结点。也就是所谓的Frame。
- 然后,计算每个Frame(也就是每个Element)的位置,这又叫layout和reflow过程。
3)最后通过调用操作系统Native GUI的API绘制。
DOM解析
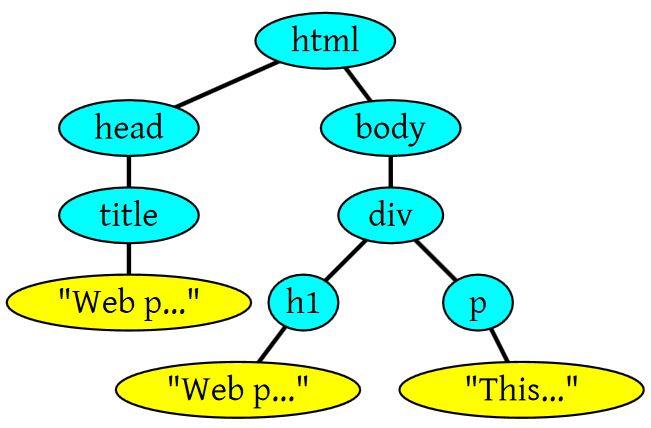
HTML的DOM Tree解析如下:
<html>
<html>
<head>
<title>Web page parsing</title>
</head>
<body>
<div>
<h1>Web page parsing</h1>
<p>This is an example Web page.</p>
</div>
</body>
</html>
上面这段HTML会解析成这样:
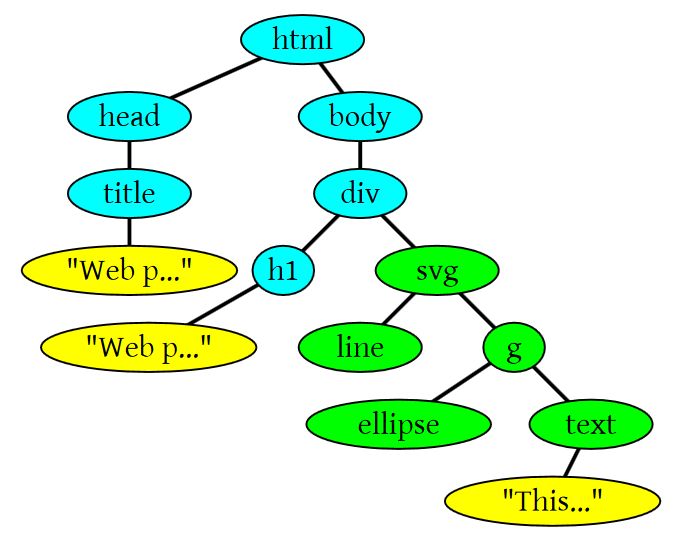
下面是另一个有SVG标签的情况。
CSS解析
CSS的解析大概是下面这个样子(下面主要说的是Gecko也就是Firefox的玩法),假设我们有下面的HTML文档: