浏览器的渲染原理简介
看到这个标题大家一定会想到这篇神文《How Browsers Work》,这篇文章把浏览器的很多细节讲得很细,而且也被翻译成了中文。为什么我还想写一篇呢?因为两个原因,
1)这篇文章太长了,阅读成本太大,不能一口气读完。
2)花了大力气读了这篇文章后可以了解很多,但似乎对工作没什么帮助。
所以,我准备写下这篇文章来解决上述两个问题。希望你能在上班途中,或是坐马桶时就能读完,并能从中学会一些能用在工作上的东西。
目录
浏览器工作大流程
废话少说,先来看个图:
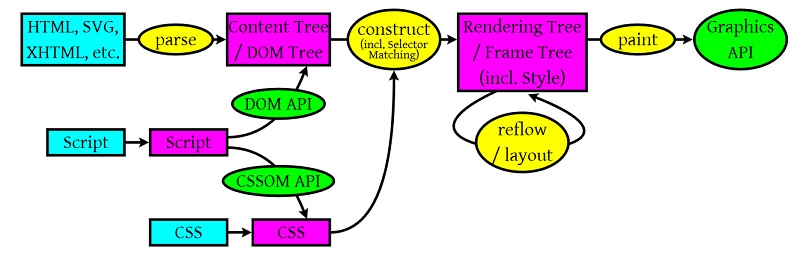
从上面这个图中,我们可以看到那么几个事:
1)浏览器会解析三个东西:
- 一个是HTML/SVG/XHTML,事实上,Webkit有三个C++的类对应这三类文档。解析这三种文件会产生一个DOM Tree。
- CSS,解析CSS会产生CSS规则树。
- Javascript,脚本,主要是通过DOM API和CSSOM API来操作DOM Tree和CSS Rule Tree.
2)解析完成后,浏览器引擎会通过DOM Tree 和 CSS Rule Tree 来构造 Rendering Tree。注意:
- Rendering Tree 渲染树并不等同于DOM树,因为一些像Header或display:none的东西就没必要放在渲染树中了。
- CSS 的 Rule Tree主要是为了完成匹配并把CSS Rule附加上Rendering Tree上的每个Element。也就是DOM结点。也就是所谓的Frame。
- 然后,计算每个Frame(也就是每个Element)的位置,这又叫layout和reflow过程。
3)最后通过调用操作系统Native GUI的API绘制。
DOM解析
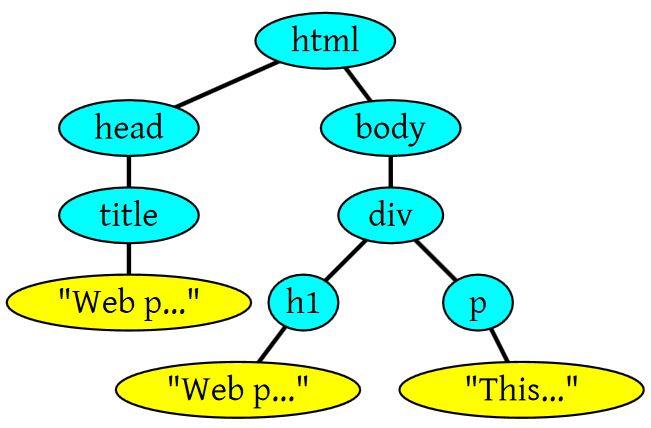
HTML的DOM Tree解析如下:
<html>
<html>
<head>
<title>Web page parsing</title>
</head>
<body>
<div>
<h1>Web page parsing</h1>
<p>This is an example Web page.</p>
</div>
</body>
</html>
上面这段HTML会解析成这样:
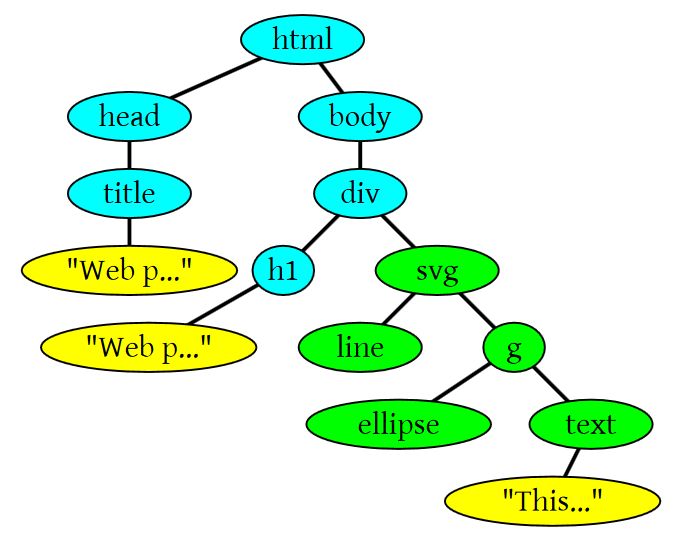
下面是另一个有SVG标签的情况。
CSS解析
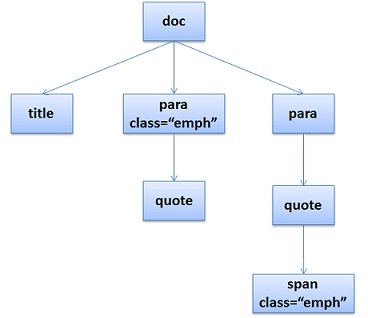
CSS的解析大概是下面这个样子(下面主要说的是Gecko也就是Firefox的玩法),假设我们有下面的HTML文档:
<doc> <title>A few quotes</title> <para> Franklin said that <quote>"A penny saved is a penny earned."</quote> </para> <para> FDR said <quote>"We have nothing to fear but <span>fear itself.</span>"</quote> </para> </doc>
于是DOM Tree是这个样子:
然后我们的CSS文档是这样的:
/* rule 1 */ doc { display: block; text-indent: 1em; }
/* rule 2 */ title { display: block; font-size: 3em; }
/* rule 3 */ para { display: block; }
/* rule 4 */ [class="emph"] { font-style: italic; }
于是我们的CSS Rule Tree会是这个样子:
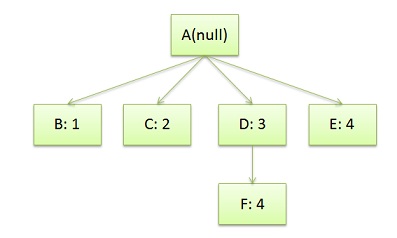
注意,图中的第4条规则出现了两次,一次是独立的,一次是在规则3的子结点。所以,我们可以知道,建立CSS Rule Tree是需要比照着DOM Tree来的。CSS匹配DOM Tree主要是从右到左解析CSS的Selector,好多人以为这个事会比较快,其实并不一定。关键还看我们的CSS的Selector怎么写了。
注意:CSS匹配HTML元素是一个相当复杂和有性能问题的事情。所以,你就会在N多地方看到很多人都告诉你,DOM树要小,CSS尽量用id和class,千万不要过渡层叠下去,……
通过这两个树,我们可以得到一个叫Style Context Tree,也就是下面这样(把CSS Rule结点Attach到DOM Tree上):
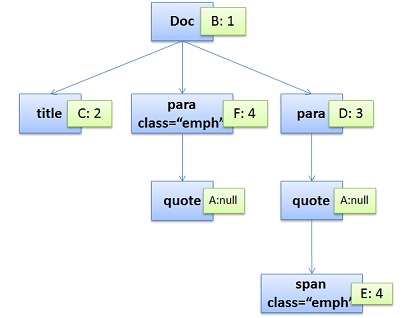
所以,Firefox基本上来说是通过CSS 解析 生成 CSS Rule Tree,然后,通过比对DOM生成Style Context Tree,然后Firefox通过把Style Context Tree和其Render Tree(Frame Tree)关联上,就完成了。注意:Render Tree会把一些不可见的结点去除掉。而Firefox中所谓的Frame就是一个DOM结点,不要被其名字所迷惑了。
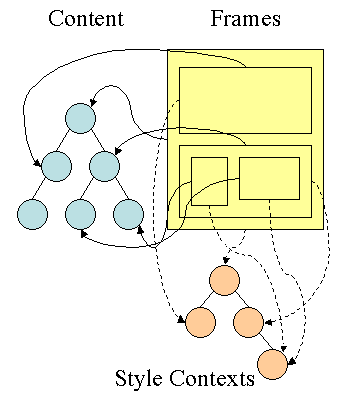
注:Webkit不像Firefox要用两个树来干这个,Webkit也有Style对象,它直接把这个Style对象存在了相应的DOM结点上了。
渲染
渲染的流程基本上如下(黄色的四个步骤):
- 计算CSS样式
- 构建Render Tree
- Layout – 定位坐标和大小,是否换行,各种position, overflow, z-index属性 ……
- 正式开画
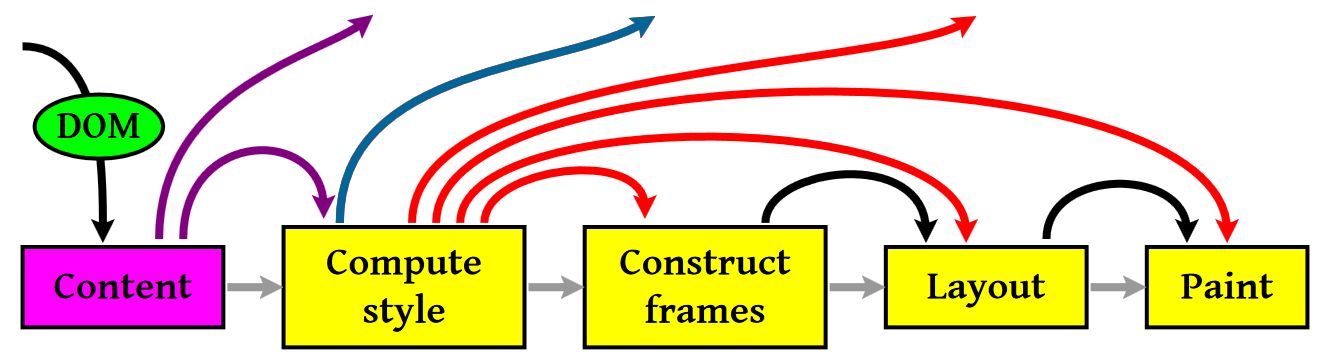
注意:上图流程中有很多连接线,这表示了Javascript动态修改了DOM属性或是CSS属会导致重新Layout,有些改变不会,就是那些指到天上的箭头,比如,修改后的CSS rule没有被匹配到,等。
这里重要要说两个概念,一个是Reflow,另一个是Repaint。这两个不是一回事。
- Repaint——屏幕的一部分要重画,比如某个CSS的背景色变了。但是元素的几何尺寸没有变。
- Reflow——意味着元件的几何尺寸变了,我们需要重新验证并计算Render Tree。是Render Tree的一部分或全部发生了变化。这就是Reflow,或是Layout。(HTML使用的是flow based layout,也就是流式布局,所以,如果某元件的几何尺寸发生了变化,需要重新布局,也就叫reflow)reflow 会从<html>这个root frame开始递归往下,依次计算所有的结点几何尺寸和位置,在reflow过程中,可能会增加一些frame,比如一个文本字符串必需被包装起来。
下面是一个打开Wikipedia时的Layout/reflow的视频(注:HTML在初始化的时候也会做一次reflow,叫 intial reflow),你可以感受一下:
所以,下面这些动作有很大可能会是成本比较高的。
- 当你增加、删除、修改DOM结点时,会导致Reflow或Repaint
- 当你移动DOM的位置,或是搞个动画的时候。
- 当你修改CSS样式的时候。
- 当你Resize窗口的时候(移动端没有这个问题),或是滚动的时候。
- 当你修改网页的默认字体时。
注:display:none会触发reflow,而visibility:hidden只会触发repaint,因为没有发现位置变化。
多说两句关于滚屏的事,通常来说,如果在滚屏的时候,我们的页面上的所有的像素都会跟着滚动,那么性能上没什么问题,因为我们的显卡对于这种把全屏像素往上往下移的算法是很快。但是如果你有一个fixed的背景图,或是有些Element不跟着滚动,有些Elment是动画,那么这个滚动的动作对于浏览器来说会是相当相当痛苦的一个过程。你可以看到很多这样的网页在滚动的时候性能有多差。因为滚屏也有可能会造成reflow。
基本上来说,reflow有如下的几个原因:
- Initial。网页初始化的时候。
- Incremental。一些Javascript在操作DOM Tree时。
- Resize。其些元件的尺寸变了。
- StyleChange。如果CSS的属性发生变化了。
- Dirty。几个Incremental的reflow发生在同一个frame的子树上。
好了,我们来看一个示例吧:
[javascript]var bstyle = document.body.style; // cache
bstyle.padding = "20px"; // reflow, repaint
bstyle.border = "10px solid red"; // 再一次的 reflow 和 repaint
bstyle.color = "blue"; // repaint
bstyle.backgroundColor = "#fad"; // repaint
bstyle.fontSize = "2em"; // reflow, repaint
// new DOM element – reflow, repaint
document.body.appendChild(document.createTextNode(‘dude!’));[/javascript]
当然,我们的浏览器是聪明的,它不会像上面那样,你每改一次样式,它就reflow或repaint一次。一般来说,浏览器会把这样的操作积攒一批,然后做一次reflow,这又叫异步reflow或增量异步reflow。但是有些情况浏览器是不会这么做的,比如:resize窗口,改变了页面默认的字体,等。对于这些操作,浏览器会马上进行reflow。
但是有些时候,我们的脚本会阻止浏览器这么干,比如:如果我们请求下面的一些DOM值:
- offsetTop, offsetLeft, offsetWidth, offsetHeight
- scrollTop/Left/Width/Height
- clientTop/Left/Width/Height
- IE中的 getComputedStyle(), 或 currentStyle
因为,如果我们的程序需要这些值,那么浏览器需要返回最新的值,而这样一样会flush出去一些样式的改变,从而造成频繁的reflow/repaint。
减少reflow/repaint
下面是一些Best Practices:
1)不要一条一条地修改DOM的样式。与其这样,还不如预先定义好css的class,然后修改DOM的className。
[javascript]// bad
var left = 10,
top = 10;
el.style.left = left + "px";
el.style.top = top + "px";
// Good
el.className += " theclassname";
// Good
el.style.cssText += "; left: " + left + "px; top: " + top + "px;";[/javascript]
2)把DOM离线后修改。如:
- 使用documentFragment 对象在内存里操作DOM
- 先把DOM给display:none(有一次reflow),然后你想怎么改就怎么改。比如修改100次,然后再把他显示出来。
- clone一个DOM结点到内存里,然后想怎么改就怎么改,改完后,和在线的那个的交换一下。
3)不要把DOM结点的属性值放在一个循环里当成循环里的变量。不然这会导致大量地读写这个结点的属性。
4)尽可能的修改层级比较低的DOM。当然,改变层级比较底的DOM有可能会造成大面积的reflow,但是也可能影响范围很小。
5)为动画的HTML元件使用fixed或absoult的position,那么修改他们的CSS是不会reflow的。
6)千万不要使用table布局。因为可能很小的一个小改动会造成整个table的重新布局。
In this manner, the user agent can begin to lay out the table once the entire first row has been received. Cells in subsequent rows do not affect column widths. Any cell that has content that overflows uses the ‘overflow’ property to determine whether to clip the overflow content.
This algorithm may be inefficient since it requires the user agent to have access to all the content in the table before determining the final layout and may demand more than one pass.
几个工具和几篇文章
有时候,你会也许会发现在IE下,你不知道你修改了什么东西,结果CPU一下子就上去了到100%,然后过了好几秒钟repaint/reflow才完成,这种事情以IE的年代时经常发生。所以,我们需要一些工具帮我们看看我们的代码里有没有什么不合适的东西。
- Chrome下,Google的SpeedTracer是个非常强悍的工作让你看看你的浏览渲染的成本有多大。其实Safari和Chrome都可以使用开发者工具里的一个Timeline的东东。
- Firefox下这个基于Firebug的叫Firebug Paint Events的插件也不错。
- IE下你可以用一个叫dynaTrace的IE扩展。
最后,别忘了下面这几篇提高浏览器性能的文章:
- Google – Web Performance Best Practices
- Yahoo – Best Practices for Speeding Up Your Web Site
- Steve Souders – 14 Rules for Faster-Loading Web Sites
参考
- David Baron的演讲:Fast CSS: How Browsers Lay Out Web Pages:slideshow, all slides, audio (MP3), Session page, Lanyrd page
- How Browsers Work: http://taligarsiel.com/Projects/howbrowserswork1.htm
- Mozilla 的 Style System Overview:https://developer.mozilla.org/en-US/docs/Style_System_Overview
- Mozilla 的 Note of reflow: http://www-archive.mozilla.org/newlayout/doc/reflow.html
- Rendering: repaint, reflow/relayout, restyle:http://www.phpied.com/rendering-repaint-reflowrelayout-restyle/
- Effective Rendering CSS:http://css-tricks.com/efficiently-rendering-css/
- Webkit Rendering文档:http://trac.webkit.org/wiki/WebCoreRendering
(转载本站文章请注明作者和出处 酷 壳 – CoolShell ,请勿用于任何商业用途)





 (72 人打了分,平均分: 4.35 )
(72 人打了分,平均分: 4.35 )
《浏览器的渲染原理简介》的相关评论
无语了,什么都被你看穿了
博主不管前端还是后台都那么精通啊
前端和后端有差别吗?
很棒。
有一个笔误,
“5)为动画的HTML元件使用fixed或absoult的position,那么修改他们的CSS是不会reflow的。”
“absoult” -> “absolute”
谢谢!我就不改了。这样可以看看哪些人抄了我的文章。
还真是完全抄了你的文章,还是腾讯的前端团队,还写的是他们自己写的…
https://imweb.io/topic/56841c864c44bcc56092e3fa
牛文
Emacs 的高亮显示之类的也在做语义分析,这可是编译理论的一大部分,firefox 的代码下过一次 300多MB 毫无头绪,作罢!定要再做研读。
不过感觉 博主的研究是广开叶,浅尝辄止,却又入目三分
陈老师真是好全面,这种积淀不是一朝一夕呀,向您学习!
最近想提高下前端技术,一直没空,看到楼主这么有激情,自叹不如哎。
谢谢博主分享这么好的东西,受益良多。
总结得比较到位,不过有两点是不是有点不妥(呵呵,有点吹毛求疵了):
1:“然后,计算每个Frame(也就是每个Element)的位置,这又叫layout和reflow过程。”
我觉得计算frame位置是在构建render tree的时候完成的,layout或reflow是在根据位置大小信息排布frame元素。
2:“而Firefox中所谓的Frame就是一个DOM结点,不要被其名字所迷惑了。”
这个其实真实的情况我也不是特别了解,但是根据“how browser works”原文中的描述,frame应该不能和dom节点一一对应,一个dom节点可能会构建出多个frame元素
“There are DOM elements which correspond to several visual objects. These are usually elements with complex structure that cannot be described by a single rectangle. For example, the “select” element has 3 renderers – one for the display area, one for the drop down list box and one for the button. Also when text is broken into multiple lines because the width is not sufficient for one line, the new lines will be added as extra renderers. ”
“display:none(有一次repaint)”筆誤吧,應該是 visibility:hidden 會repaint
很有用,不只是内容。
很有用,不只是内容呢
f
很多人都不懂这些原理的东西,但面试的时候最喜欢问这些。
觉得前后有一点对应不上,前面写到“解析完成后,浏览器引擎会通过DOM Tree 和 CSS Rule Tree 来构造 Rendering Tree”,但是后面的详细介绍再没有提到“Rendering Tree”。我的理解是,后面说的“通过这两个树(dom tree & css ruler tree),我们可以得到一个叫Style Context Tree,也就是下面这样(把CSS Rule结点Attach到DOM Tree上)”,后面所说的“Style Context Tree” 是不是和前面的 “Rendering Tree”概念等同?
写了会代码切到微博,尾随过来看看这篇短文,果然既不费脑力又收获了一些基础知识,面试时起码能侃上两句
@陈皓
看到前端的CSS就头大,JS还好,挺喜欢的
知道两点:
1>.为什么提倡使用div布局,而不是table。因为table的效率太差;
2>.多使用id class,修改层级低的元素。
PS:皓哥用的什么操作系统?web开发,linux好还是windows?
很精彩,通俗易懂。希望看到更多这样的技术文章
很好的文章…以前只知道IE和非IE用了不同的渲染引擎,但是渲染引擎干什么的却不知道呢…
耗子叔,真太牛逼了。
不错,我们团队在学习
@陈皓
我追求前后端都要懂,但我承认,我做前端不好看,这是美术造诣不行吧,虽然能理解原理。
说的真好!又一次深入的了解了浏览器的工作流程,膜拜皓叔!
感谢博主的分享,学了不少东西
很有用的文章,学习了,牛
看起来好麻烦的样子~~
IE6下 用hack做的 fixed 元素会闪动,就是 reflow的原因吗?
b/s应用做到深入了,才发现。。。。。
耗子前辈前几天要教几个妹子技术,难道这是第一篇?
@陈皓
能详细的说下么?我认为前端是网页的显示,以及输入输出的交互,而后台是数据的处理,以及事件响应的处理逻辑。本人初学对这两个概念理解的还不是很透彻,能否点拨下,该从那个角度来理解”前端和后端没有差别“。十分感谢~
不错,本来还以为不是浏览器开发人员看这个没什么用,现在提醒了我不要只想着优化 CSS ,还得优化一下网页框架。:D
真心觉得没看明白。。。。。有点像是看鲁迅的散文。。。。你知道他说什么,但是又不知道他真的想表达什么
陈老师…我想歪了…
@李文科
这是知识和经验不够的表现。一篇专业的学术论文,在一个小学生五年级生眼里,也是至少95%的字都认识的。
@zawdd
前端就是浏览器(用户端),后端就是服务器(服务端),两者配合才能干好事,因此只懂其中一个是很不现实的。
即使后端的安全和效率做得再好,前端不行的话照样说明做了个糟糕的产品,反之亦然。
就算是找个网页美工,也要找懂一点网页原理的,找美工的那位程序员,也要懂一些网页原理才能指导美工应该怎么修改。
神啊 为什么牛人总是很牛呢 哎 什么时候能达到这种境界啊
您好,请允许我说我确实没太看懂,我理解的是,我们要知道浏览器渲染的原理,然后怎么样优化前端的渲染技术,有好的前段框架,会有效地减少内存占用,加上后台的有效支持,这样我们就可以进一步提高浏览器的性能,这对于手机而言,尤为重要。我这样的理解对吗?我是一个手机浏览器的tester新手,还有很多需要学习的地方,请多指教。
这是我印象最深的地方
下面是一些Best Practices:
1)不要一条一条地修改DOM的样式。与其这样,还不如预先定义好css的class,然后修改DOM的className。
1234567891011 // bad var left = 10, top = 10; el.style.left = left + “px”; el.style.top = top + “px”; // Good el.className += ” theclassname”; // Good el.style.cssText += “; left: ” + left + “px; top: ” + top + “px;”;
以前一直以为浏览器内核就是xml解析器,读完之后受益不少,博主的插图做的很棒啊
每次来coolshell都能学到很多。
很喜欢看酷壳的文章,内容丰富,解释到位。只是大神最近总提坐在马桶上看,习惯边啃包子边看的我感觉压力略大啊。。。。
先顶
“先把DOM给display:none(有一次reflow),然后你想怎么改就怎么改。比如修改100次,然后再把他显示出来。”
如果用visibility会不会更好呢
“为动画的HTML元件使用fixed或absoult的position,那么修改他们的CSS是不会reflow的”
这样是不是可以理解为,只要不在 0 z轴上的元素,都不会引起浏览器的reflow呢
“所以,你就会在N多地方看到很多人都告诉你,DOM树要小,CSS尽量用id和class,千万不要过渡层叠下去”
最近也在尽量避免用过渡层叠,但这样的话,页面中就会有大量的元素都有class,页面的容量就会增大影响下载,不知道陈老师有没有好的折中办法?
@陈皓
我会抄你的文章, 注意一下我哦!!!!! :-)
精髓在于一次遍历,不走回头路。很早以前看过原版
浏览器的渲染是不是就是页面打开的速度??