Go 编程模式:错误处理
 错误处理一直以一是编程必需要面对的问题,错误处理如果做的好的话,代码的稳定性会很好。不同的语言有不同的出现处理的方式。Go语言也一样,在本篇文章中,我们来讨论一下Go语言的出错出处,尤其是那令人抓狂的
错误处理一直以一是编程必需要面对的问题,错误处理如果做的好的话,代码的稳定性会很好。不同的语言有不同的出现处理的方式。Go语言也一样,在本篇文章中,我们来讨论一下Go语言的出错出处,尤其是那令人抓狂的 if err != nil 。
在正式讨论Go代码里满屏的 if err != nil 怎么办这个事之前,我想先说一说编程中的错误处理。这样可以让大家在更高的层面理解编程中的错误处理。
本文是全系列中第2 / 10篇:Go编程模式
C语言的错误检查
首先,我们知道,处理错误最直接的方式是通过错误码,这也是传统的方式,在过程式语言中通常都是用这样的方式处理错误的。比如 C 语言,基本上来说,其通过函数的返回值标识是否有错,然后通过全局的 errno 变量并配合一个 errstr 的数组来告诉你为什么出错。
为什么是这样的设计?道理很简单,除了可以共用一些错误,更重要的是这其实是一种妥协。比如:read(), write(), open() 这些函数的返回值其实是返回有业务逻辑的值。也就是说,这些函数的返回值有两种语义,一种是成功的值,比如 open() 返回的文件句柄指针 FILE* ,或是错误 NULL。这样会导致调用者并不知道是什么原因出错了,需要去检查 errno 来获得出错的原因,从而可以正确地处理错误。
一般而言,这样的错误处理方式在大多数情况下是没什么问题的。但是也有例外的情况,我们来看一下下面这个 C 语言的函数:

 (44 人打了分,平均分: 4.09 )
(44 人打了分,平均分: 4.09 )
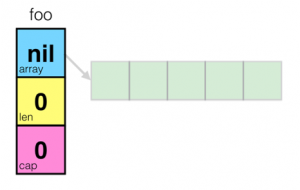 熟悉C/C++的同学一定会知道,在结构体里用数组指针的问题——数据会发生共享!下面我们来看一下slice的一些操作
熟悉C/C++的同学一定会知道,在结构体里用数组指针的问题——数据会发生共享!下面我们来看一下slice的一些操作 (50 人打了分,平均分: 4.30 )
(50 人打了分,平均分: 4.30 ) 总是有很多很多人来问我对Rust语言怎么看的问题,在各种地方被at,其实,我不是很想表达我的想法。因为在不同的角度,你会看到不同的东西。编程语言这个东西,老实说很难评价,在学术上来说,Lisp就是很好的语言,然而在工程使用的时候,你会发现Lisp没什么人用,而Javascript或是PHP这样在学术很糟糕设计的语言反而成了主流,你觉得C++很反人类,在我看来,C++有很多不错的设计,而且对于了解编程语言和编译器的和原理非常有帮助。但是C++也很危险,所以,出现在像Java或Go 语言来改善它,Rust本质上也是在改善C++的。他们各自都有各自的长处和优势。
总是有很多很多人来问我对Rust语言怎么看的问题,在各种地方被at,其实,我不是很想表达我的想法。因为在不同的角度,你会看到不同的东西。编程语言这个东西,老实说很难评价,在学术上来说,Lisp就是很好的语言,然而在工程使用的时候,你会发现Lisp没什么人用,而Javascript或是PHP这样在学术很糟糕设计的语言反而成了主流,你觉得C++很反人类,在我看来,C++有很多不错的设计,而且对于了解编程语言和编译器的和原理非常有帮助。但是C++也很危险,所以,出现在像Java或Go 语言来改善它,Rust本质上也是在改善C++的。他们各自都有各自的长处和优势。 好久没有写一些微观方面的文章了,今天写一篇关于CPU Cache相关的文章,这篇文章比较长,主要分成这么几个部分:基础知识、缓存的命中、缓存的一致性、相关的代码示例和延伸阅读。其中会讲述一些多核 CPU 的系统架构以及其原理,包括对程序性能上的影响,以及在进行并发编程的时候需要注意到的一些问题。这篇文章我会尽量地写简单和通俗易懂一些,主要是讲清楚相关的原理和问题,而对于一些细节和延伸阅读我会在文章最后会给出相关的资源。
好久没有写一些微观方面的文章了,今天写一篇关于CPU Cache相关的文章,这篇文章比较长,主要分成这么几个部分:基础知识、缓存的命中、缓存的一致性、相关的代码示例和延伸阅读。其中会讲述一些多核 CPU 的系统架构以及其原理,包括对程序性能上的影响,以及在进行并发编程的时候需要注意到的一些问题。这篇文章我会尽量地写简单和通俗易懂一些,主要是讲清楚相关的原理和问题,而对于一些细节和延伸阅读我会在文章最后会给出相关的资源。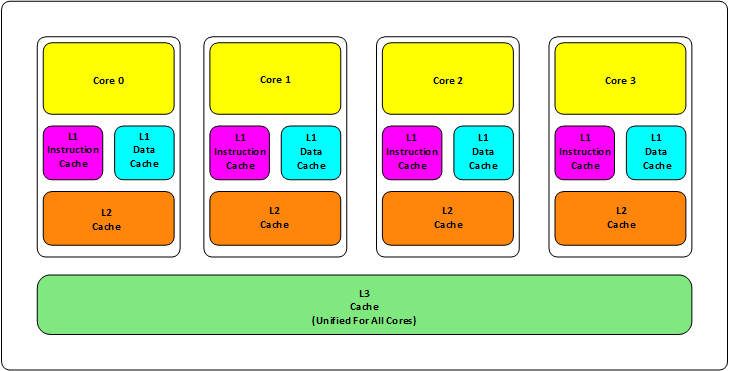
 前些天,StackOverflow 发布了
前些天,StackOverflow 发布了  上个月,作为 Go 语言的三位创始人之一,Unix 老牌黑客罗勃·派克(Rob Pike)在新文章“
上个月,作为 Go 语言的三位创始人之一,Unix 老牌黑客罗勃·派克(Rob Pike)在新文章“ 随着Apache、百度、Wordpress都在和Facebook的React.js以及其专利许可证划清界限,似乎大家又在讨论Facebook的这个BSD+PATENT的许可证问题了。这让我想起了之前在Medium读过的一篇文章——《
随着Apache、百度、Wordpress都在和Facebook的React.js以及其专利许可证划清界限,似乎大家又在讨论Facebook的这个BSD+PATENT的许可证问题了。这让我想起了之前在Medium读过的一篇文章——《 今天,我把CoolShell变成https的安全访问了。我承认这件事有点晚了,因为之前的HTTP的问题也有网友告诉我,被国内的电信运营商在访问我的网站时加入了一些弹窗广告。另外,HTTP的网站在搜索引擎中的rank会更低。所以,这事早就应该干了。现在用HTTP访问CoolShell会被得到一个 301 的HTTPS的跳转。下面我分享一下启用HTTPS的过程。
今天,我把CoolShell变成https的安全访问了。我承认这件事有点晚了,因为之前的HTTP的问题也有网友告诉我,被国内的电信运营商在访问我的网站时加入了一些弹窗广告。另外,HTTP的网站在搜索引擎中的rank会更低。所以,这事早就应该干了。现在用HTTP访问CoolShell会被得到一个 301 的HTTPS的跳转。下面我分享一下启用HTTPS的过程。
 之前写过一篇《
之前写过一篇《