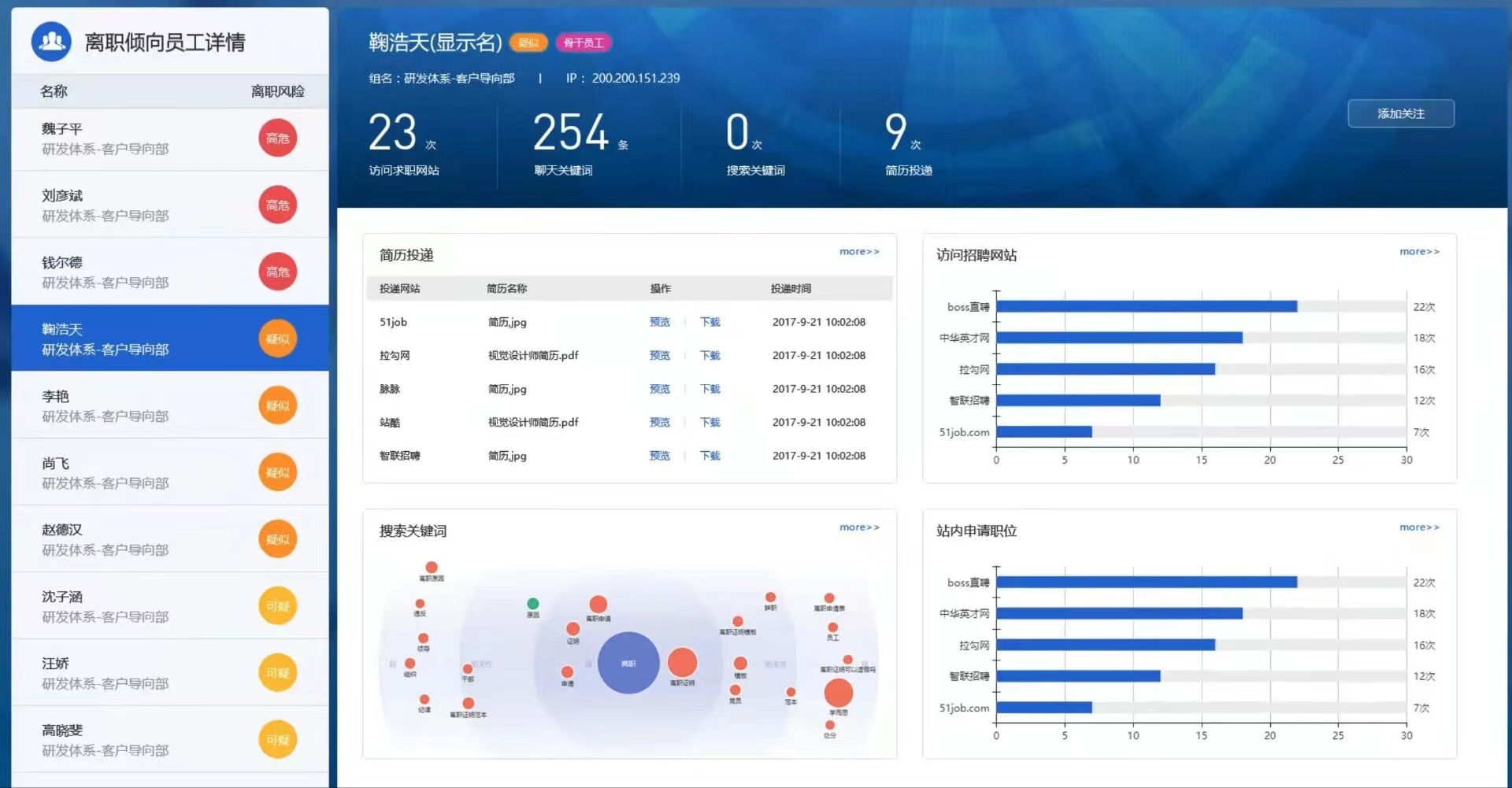
是微服务架构不香还是云不香?
 这两天技术圈里热议的一件事就是Amazon的流媒体平台Prime Video在2023年3月22日发布了一篇技术博客《规模化Prime Video的音视频监控服务,成本降低90%》,副标题:“从分布式微服务架构到单体应用程序的转变有助于实现更高的规模、弹性和降低成本”,有人把这篇文章在五一期间转到了reddit 和 hacker news 上,在Reddit上热议。这种话题与业内推崇的微服务架构形成了鲜明的对比。从“微服务架构”转“单体架构”,还是Amazon干的,这个话题足够劲爆。然后DHH在刚喷完Typescript后继续发文《即便是亚马逊也无法理解Servless或微服务》,继续抨击微服务架构,于是,瞬间引爆技术圈,登上技术圈热搜。
这两天技术圈里热议的一件事就是Amazon的流媒体平台Prime Video在2023年3月22日发布了一篇技术博客《规模化Prime Video的音视频监控服务,成本降低90%》,副标题:“从分布式微服务架构到单体应用程序的转变有助于实现更高的规模、弹性和降低成本”,有人把这篇文章在五一期间转到了reddit 和 hacker news 上,在Reddit上热议。这种话题与业内推崇的微服务架构形成了鲜明的对比。从“微服务架构”转“单体架构”,还是Amazon干的,这个话题足够劲爆。然后DHH在刚喷完Typescript后继续发文《即便是亚马逊也无法理解Servless或微服务》,继续抨击微服务架构,于是,瞬间引爆技术圈,登上技术圈热搜。
今天上午有好几个朋友在微信里转了三篇文章给我,如下所示:
看看这些标题就知道这些文章要的是流量而不是好好写篇文章。看到第二篇,你还真当 Prime Video 就是 Amazon 的全部么?然后,再看看这些文章后面的跟风评论,我觉得有 80%的人只看标题,而且是连原文都不看的。所以,我想我得写篇文章了……

 (651 人打了分,平均分: 4.31 )
(651 人打了分,平均分: 4.31 ) 两个月前,我试着想用 ChatGPT 帮我写篇文章《
两个月前,我试着想用 ChatGPT 帮我写篇文章《
 这两天在网络上又有一个东西火了,Twitter 的创始人
这两天在网络上又有一个东西火了,Twitter 的创始人  写一篇与技术无关的文章,供大家参考。我住北京朝阳,从上周三开始我家一家三口陆续发烧生病,自测抗原后,都是阳性。好消息是,这个奥密克戎跟一般的病毒性感冒差不多,没什么可怕的,不过,整个过程除了发病之外还有一些别的因为感染带出来的事,大家也需要知晓,以准备好,以免造成生活的不便,更好的照顾好自己和家人。
写一篇与技术无关的文章,供大家参考。我住北京朝阳,从上周三开始我家一家三口陆续发烧生病,自测抗原后,都是阳性。好消息是,这个奥密克戎跟一般的病毒性感冒差不多,没什么可怕的,不过,整个过程除了发病之外还有一些别的因为感染带出来的事,大家也需要知晓,以准备好,以免造成生活的不便,更好的照顾好自己和家人。 (79 人打了分,平均分: 4.22 )
(79 人打了分,平均分: 4.22 ) 很早前就想写一篇关于eBPF的文章,但是迟迟没有动手,这两天有点时间,所以就来写一篇,这文章主要还是简单的介绍eBPF 是用来干什么的,并通过几个示例来介绍是怎么玩的,这个技术非常非常之强,Linux 操作系统的观测性实在是太强大了,并在 BCC 加持下变得一览无余。这个技术不是一般的运维人员或是系统管理员可以驾驭的,这个还是要有底层系统知识并有一定开发能力的技术人员才能驾驭的了的。我在这篇文章的最后给了个彩蛋。
很早前就想写一篇关于eBPF的文章,但是迟迟没有动手,这两天有点时间,所以就来写一篇,这文章主要还是简单的介绍eBPF 是用来干什么的,并通过几个示例来介绍是怎么玩的,这个技术非常非常之强,Linux 操作系统的观测性实在是太强大了,并在 BCC 加持下变得一览无余。这个技术不是一般的运维人员或是系统管理员可以驾驭的,这个还是要有底层系统知识并有一定开发能力的技术人员才能驾驭的了的。我在这篇文章的最后给了个彩蛋。 这两天跟
这两天跟  今天来讲一讲TCP 的
今天来讲一讲TCP 的  今天跟大家分享一个etcd的内存大量占用的问题,这是前段时间在我们开源软件Easegress中遇到的问题,问题是比较简单的,但是我还想把前因后果说一下,包括,为什么要用etcd,使用etcd的用户场景,包括etcd的一些导致内存占用比较大的设计,以及最后一些建议。希望这篇文章不仅仅只是让你看到了一个简单的内存问题,还能让你有更多的收获。当然,也欢迎您关注我们的开源软件,给我们一些鼓励。
今天跟大家分享一个etcd的内存大量占用的问题,这是前段时间在我们开源软件Easegress中遇到的问题,问题是比较简单的,但是我还想把前因后果说一下,包括,为什么要用etcd,使用etcd的用户场景,包括etcd的一些导致内存占用比较大的设计,以及最后一些建议。希望这篇文章不仅仅只是让你看到了一个简单的内存问题,还能让你有更多的收获。当然,也欢迎您关注我们的开源软件,给我们一些鼓励。