bash代码注入的安全漏洞
 很多人或许对上半年发生的安全问题“心脏流血”(Heartbleed Bug)事件记忆颇深,这两天,又出现了另外一个“毁灭级”的漏洞——Bash软件安全漏洞。这个漏洞由法国GNU/Linux爱好者Stéphane Chazelas所发现。随后,美国电脑紧急应变中心(US-CERT)、红帽以及多家从事安全的公司于周三(北京时间9月24日)发出警告。 关于这个安全漏洞的细节可参看美国政府计算安全的这两个漏洞披露:CVE-2014-6271 和 CVE-2014-7169。
很多人或许对上半年发生的安全问题“心脏流血”(Heartbleed Bug)事件记忆颇深,这两天,又出现了另外一个“毁灭级”的漏洞——Bash软件安全漏洞。这个漏洞由法国GNU/Linux爱好者Stéphane Chazelas所发现。随后,美国电脑紧急应变中心(US-CERT)、红帽以及多家从事安全的公司于周三(北京时间9月24日)发出警告。 关于这个安全漏洞的细节可参看美国政府计算安全的这两个漏洞披露:CVE-2014-6271 和 CVE-2014-7169。
这个漏洞其实是非常经典的“注入式攻击”,也就是可以向 bash注入一段命令,从bash1.14 到4.3都存在这样的漏洞。我们先来看一下这个安全问题的症状。
Shellshock (CVE-2014-6271)
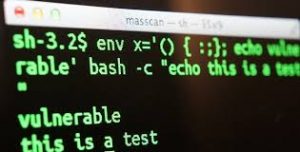
下面是一个简单的测试:
$ env VAR='() { :;}; echo Bash is vulnerable!' bash -c "echo Bash Test"
如果你发现上面这个命令在你的bash下有这样的输出,那你就说明你的bash是有漏洞的:
Bash is vulnerable! Bash Test
简单地看一下,其实就是向环境变量中注入了一段代码 echo Bash is vulnerable。关于其中的原理我会在后面给出。
很快,CVE-2014-6271的官方补丁出来的了——Bash-4.3 Official Patch 25。

 (78 人打了分,平均分: 4.50 )
(78 人打了分,平均分: 4.50 ) 1986年11月8日,有个叫Aaron Swartz的人在美国芝加哥伊利诺伊州出生。因为他父母创办了一个软件公司,所以,Aaron在3岁的时候就接触到了电脑,然后就着迷了。
1986年11月8日,有个叫Aaron Swartz的人在美国芝加哥伊利诺伊州出生。因为他父母创办了一个软件公司,所以,Aaron在3岁的时候就接触到了电脑,然后就着迷了。

 (47 人打了分,平均分: 4.02 )
(47 人打了分,平均分: 4.02 ) 我之前写过一篇叫《
我之前写过一篇叫《 这篇文章是下篇,所以如果你对TCP不熟悉的话,还请你先看看上篇《
这篇文章是下篇,所以如果你对TCP不熟悉的话,还请你先看看上篇《 TCP是一个巨复杂的协议,因为他要解决很多问题,而这些问题又带出了很多子问题和阴暗面。所以学习TCP本身是个比较痛苦的过程,但对于学习的过程却能让人有很多收获。关于TCP这个协议的细节,我还是推荐你去看
TCP是一个巨复杂的协议,因为他要解决很多问题,而这些问题又带出了很多子问题和阴暗面。所以学习TCP本身是个比较痛苦的过程,但对于学习的过程却能让人有很多收获。关于TCP这个协议的细节,我还是推荐你去看 (这篇文章缘由我的微博,我想多说一些,有些杂乱,想到哪写到哪)
(这篇文章缘由我的微博,我想多说一些,有些杂乱,想到哪写到哪)