持续部署,并不简单!
【感谢 @常新居士 投递此文 】
这几年,持续集成随着敏捷在国内的推广而持续走热,与之相伴的持续部署也一直备受关注。自前两年,持续交付这个延续性概念又闯进了国内IT圈,慢慢开始在社区和会议中展露头角。许多不明真相的群众跟风哭着喊着要“上”,而许多前CI的半吊子玩家换件衣服就接着干,有的甚至衣服都来不及换……。国内的这些土财主如果不巧请了某些所谓的战略家,除了建了一堆持续集成环境,以及每天嚷嚷着要这个要那个,混乱的状况在根本上没有得到改善。本文无意费力探讨持续集成和持续交付的概念,而是打算谈谈对于大型软件企业,以持续集成为基础实现持续部署(交付)时,所要面对的问题以及可行的解决方案。地主老财们,夜黑风正猛,山高路又远,注意脚下……
And God Said, Let there be light: and there wa— GENSIS, Charpter 1, King James
目录
一、起步
先来讲个故事……
几年前,一对留美的夫妇通过朋友找到我,让我帮忙在国内组建一个开发团队,该团队负责为其开发一款基于社交网络的客户关系管理软件,(暂且称之为项目A)。这个项目除了尚不清晰的需求范围和很紧的期限外,作为业内人士的老公Richard根据眼下流行的软件开发过程还提了诸多额外的要求:
- 功能要及早交付(以便拿去和潜在的投资人洽谈)
- 功能在部署到生产环境前要先部署的一个测试环境(Richard要试用后给予反馈)
- 功能必须经过测试(长期作为软件外包的甲方,对质量要求严格)
- 要减少后期维护的工作(美国人精贵,少雇一个是一个)
- 支持协同开发(以便维护人员及早介入)
- ……
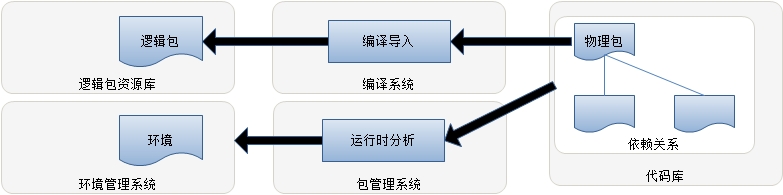
这正是持续集成所要解决的典型场景。针对Richard的要求,我们只要建立一个基于Hudson(现在叫Jenkins)+Maven +SVN 的持续集成环境(再加上持续集成所要求的测试和过程)就可以很好地满足上述要要求,此方案的结构如下:
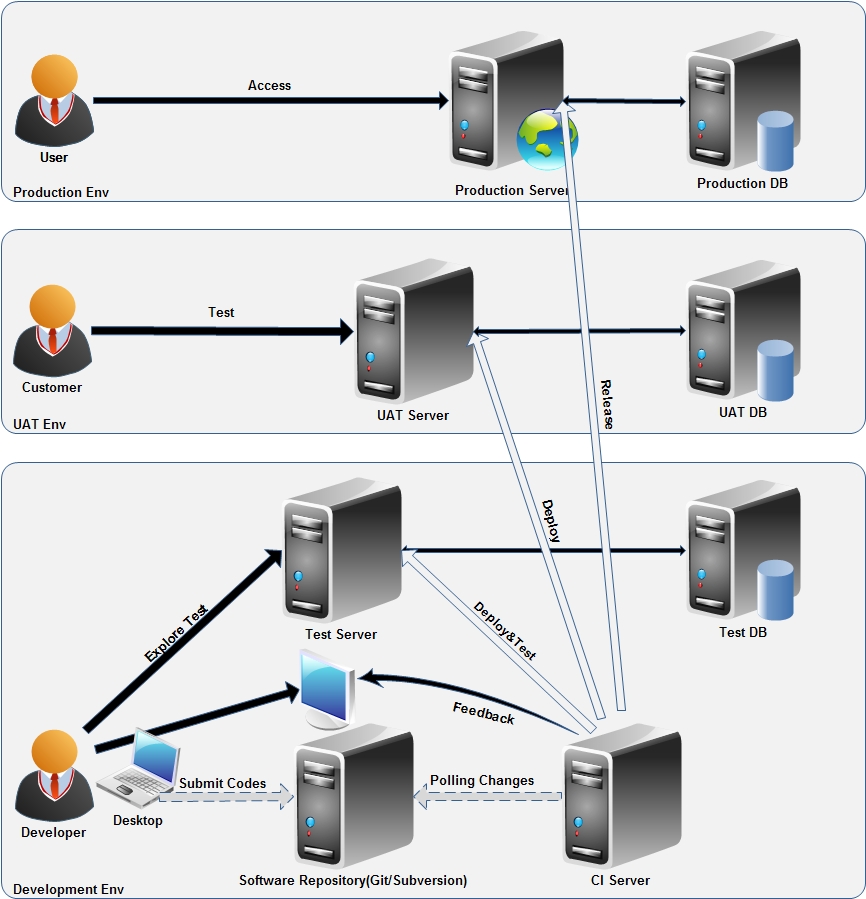
对于上述方案,让我们近距离看看各个服务器的内部情况,以及人员在这种方案下的分工协作:
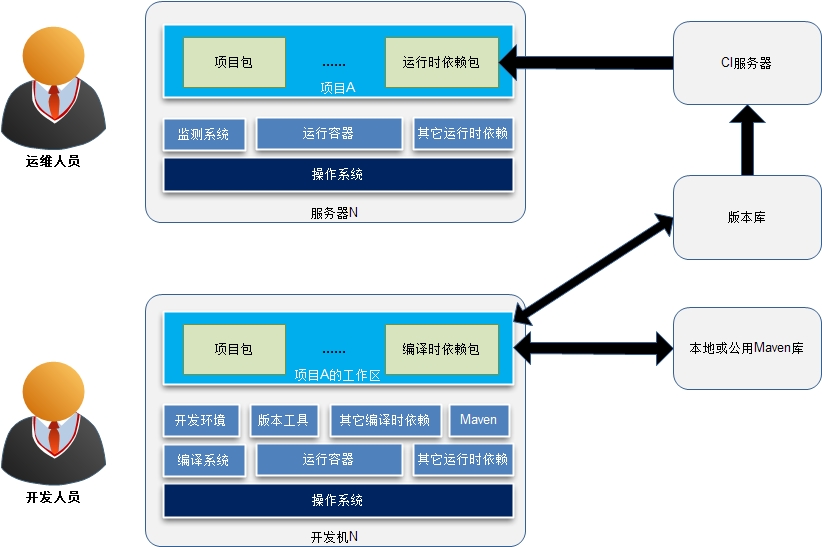
我们先谈谈上面的图中涉及的一些概念性问题:
1.1)编译时依赖和运行时依赖
从字面上不难理解这两种依赖的类型。但要注意虽然编译时依赖常常也是运行时依赖,但并不能推断出一方必然是另一方。比如,在开发的过程中需要某些提供API的Jar包,而运行时可能是具体API实现的Jar包。再者,被依赖的包会有其自身的依赖,因此,项目对这些包产生间接依赖(运行时依赖),依此类推,最终形成一个依赖树。当项目运行时,这些依赖树上的包必须全部就位。
Maven在POM中通scope来界定依赖的类型,从而帮助开发和运维人员摆脱手动处理依赖树的工作,然而运行时所依赖包最终是要安装到生产环境的,这部分工作Maven并不能自动完成。因此,一个常用方式是将运行时所依赖的包拷贝到项目文件中,比如Java Web应用的WEB-INF/lib,然后将项目总的打一个包。在安装项目包后,修改环境变量,将这些包所在的路径加入相应的环境变量中,如ClassPath。
再看个例子,现代的操作系统和其它系统框架都考虑到了运行时依赖树的处理问题,比如Ubuntu的apt-get,CentOS的yum,Ruby的RubyGem,Node的npm等等。
1.2)依赖时的复杂度
项目除了对程序包的依赖,对于运行环境也有些具体的要求,比如,Web应用需要安装和配置Web服务器,应用服务器,数据服务器等,企业应用中可能需要消息队列,缓存,定时作业,或是对其它系统以Web Service方式暴露的服务。这些可以看做项目在系统层面对外部的依赖。这些依赖有些可以由项目自行处理,而有些则是项目无法处理的,比如运行容器,操作系统等,这些是项目的运行环境。
总之,依赖的复杂度主要有两个:
- 依赖包间的版本兼容性问题。兼容性问题是软件开发的恶梦
- 间接依赖,或多重依赖问题。这个问题可以类比想像一下C++中的多重继续种出现的很多问题。
1.3)任务分工
由于项目简单,因此并不需要专门的运维人员。以一个100人左右以交付为主业(恩,就是做外包)的公司为例,由于没有任何历史项目和代码的拖累,且各个项目间也没有任何关联,故而只需要配备一个IT支持人员进行资源方面的管理:分配机器,报修,初始化系统,分配IP地址等。各个项目的运行环境、数据库、开发环境等都由具体项目的开发人员手动完成。 环境出问题怎么办?很简单,凉拌——重装系统。实际的运行效果不错。
1.4)自动化部署
由于Hudson这样的持续集成环境提供了自动编译(定时或触发式)的功能,而且可以在编译过程中提供了一些扩展点,因此通过提供一个部署用的脚本,就可以非常容易实现简单的自动化部署。
毫无疑问,持续集成就是敏捷的魔法药,它见效快、副作用小、业界的争论少。每每运用在混乱的项目中时,几周内项目就开始持续的产出经过测试的功能。对于独立项目,以持续集成为中心的持续部署绝对是不二选择。
但是,我们有没有想过,这会是一个自动化部署的通用解决方案吗?持续集成应该位于持续交付的中心吗?
二、困境
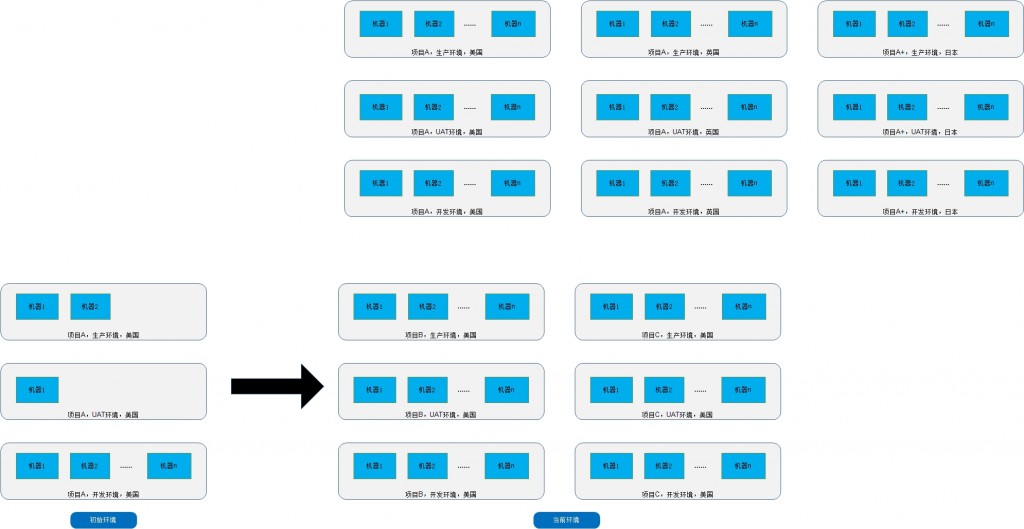
回到我们的故事:项目A上线两年后,运营业绩不错,投资人第一轮注资后,Richard的公司进行了扩张,他们对项目进行了重构,而且随着用户数量的增长,公司分别在美国、英国和日本等地建立了运营中心,并且对亚洲市场进行的定制功能开发(项目A+),接下来,公司又投入开发了团购系统(项目B)。在获得了新一轮投资后,各条本来比较简单的业务和功能线上越来越复杂,需要不断地细分,于是公司再度扩张(开发人员达到了300人,国内200多人,而运维团队主要在美国),随后又为项目A/A+的高级用户开发了问答系统(项目C)。目前,他们正准备开发手机系统。 看看下面的图,公司增长的过程中,整个项目环境也变得复杂。(注意,这里是一种逻辑结构,而在物理层面项目B和项目A的生产环境可能部署在相同的机器上)。
同时,原本单一的项目软件结构随着业务系统的增加也不再简单: 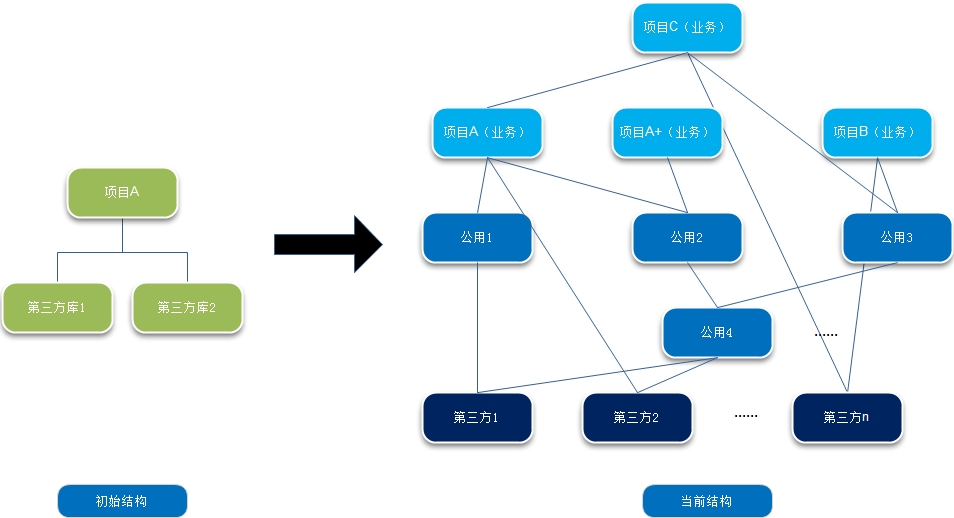
而软件间的版本依赖使这个问题变得更为复杂:
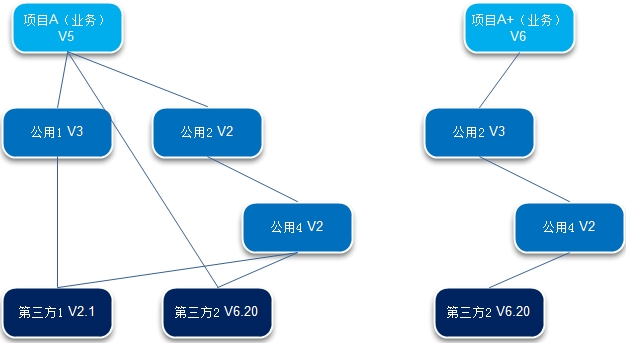
现在,Richard的公司已经不再是一条快乐的小鱼,而是渐渐成为一直庞大的巨兽。虽然只有四个产品,但公司却要支持几百台开发机,几十台生产服务器,还有对应的测试环境,数据库服务器,以及几十个开发小组,和一大堆的内部项目。我们尽可以使用持续集成来为我们完成自动化部署。但,当我们为各个项目建立起持续集成环境后,它能满足我们对于持续部署的要求吗?我们前期的工作可以简化我们今后项目的持续交付的工作的难度吗?它需要我们为之建立一个庞大的运维团队,还是可以让我们能节省下每一毛钱来投入到真正的业务价值中去?
让我们先来看看复杂的项目环境中的几个场景:
场景1:环境升级
项目A和项目B都依赖于Web容器,公司决定升级Web容器版本,而公司要升级的机器有上百台,依赖人肉升级已不现实,维护团队因此针对各种软件开发了相应的自动化脚本,但当新的软件出现时,必须要开发新的脚本。而且当同时升级若干环境软件时,则难度随之增大,手工调度的方式极易出错,当升级失败时仍需要大量人工处理。由于存在大量升级脚本,有一定的维护成本。
场景2:依赖于环境的软件升级与回滚
针对环境升级,公司为项目A和项目B开发了新的版本。但环境的升级和软件的升级不是同步进行,出错的可能性非常大(想一想间接依赖和多重依赖的情况)。当新版本部署到生产系统时,发现问题,需要回滚到之前的版本——所有运行时版本都需要回滚,而且环境也需要同步回滚。几百台机器……
场景3:运行时依赖
在第一节的方案中,我们将所有的运行时依赖都打包到一起。当项目依赖关系复杂时,这样产生的包将非常臃肿,潜在地延长了部署的时间(想一想全世有几百台服务器,一个部署计划需要部署几百兆文件的情况),而且产生冲突的可能性非常大,而且对于不同类型的项目(Java和Ruby项目)缺乏通用性。06年左右,Nortel可是拿Excel统计过运行时依赖的,牵涉若干项目组,反复多次,没有个把月真搞不定。
场景4:泛滥的部署
每个项目相关的持续集成环境都需要开发自己的部署脚本,重复投入大,而且各个项目的部署过程不一致,并且对于同一个项目无法同时满足不同目的部署要求,例如,环境或系统配置参数改变后,无需安装包,只需做清理和激活的工作。最后,持续集成只是支持了和代码修改有关的部署。
场景5:不一致的环境
简单项目中,开发环境和运行环境都由开发人员搭建,当公司变大时,系统的运行环境将由运维人员搭建,而开发环境如果由运维人员搭建则工作量太大,由开发人员自己搭建则操作复杂又容易产生不一致的情况。
场景6:热切换
对于某些部署,需要尽量减少服务的停止时间,需要在服务的同时进行部署。
这些场景只是以持续集成为中心的持续部署在面对大型企业时所遇到的部分问题。大型企业,人多,项目多,机器多,项目环境复杂,部署维护工作繁多。以持续集成为基础的部署可以解决各个项目的集成问题,却无法帮助企业应对复杂的项目环境和各种不同的部署要求。究其更本,大型企业中的部署不再是一个简单的问题,而是一个交付生态圈,基础设施和环境管理必须要纳入考虑之中。要实现真正意义上的持续部署,我们就必须把环境和项目同等对待,通通纳入管理之中。同时,部署本身要得到统一。一个好的部署机制,应该是易于建立,易于使用,易于维护。
三、任脉——环境管理
什么是环境?
系统运行所依赖和包含的一切就是其环境:硬件、操作系统,网络资源(IP地址、域名),服务容器,服务器软件配置,环境亦是,运行时依赖的命令和包,项目本身的包和配置都是环境的一部分。对于部署而言,广义上,这些通通应该纳入环境管理的范畴,但狭义上,从软件系统的角度看,一个环境就是其运行需要的软件及其配置(我们先把操作系统和网络资源当做基础设施,其在部署时已处于就位的情况)。因此:
项目A的生产环境 = 项目A本身的软件包 + 项目A运行时依赖的软件包 + 项目A运行时依赖的其它软件 + 项目A的配置信息
由于,项目本身的软件包、项目运行时依赖的软件包,以及项目运行时依赖的其它软件在本质上没有区别——都是软件,上面的定义可以进一步抽象为:
环境 = 软件包 + 配置信息
在这个定义下,我们就必须将运行环境的软件解构,并以包的形式导入到公司的整个项目资源库中,比如Apache将作为一个包被导入,而Apache依赖的其它包也将依次被导入,并建立起正确的依赖关系。而且,在导入的过程中还必须做些相应的调整,如,环境变量的读取和设置,必须来自于环境配置模块,而不要修改系统的环境变量,防止不同环境在系统环境配置上相互影响和依赖。
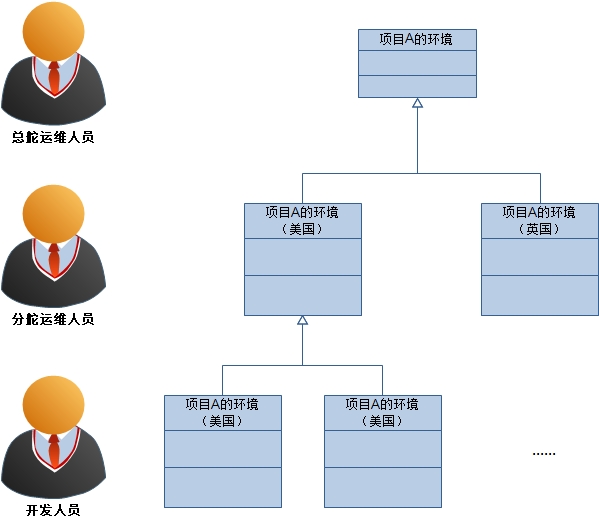
再回头审视我们的示例,项目A的生产环境可以部署在不同的区域,对于各个区域可能有定制化的设定。这就像面向对象中的类,可以通过继承使子类重用父类的公有属性和行为并添加自己特有的信息。因此,环境的概念模型如图:
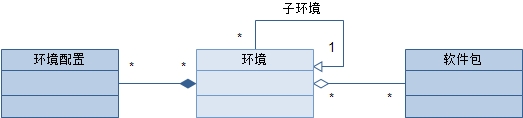
通过这样的关系,我们很容易为示例的复杂环境建立一种简单的结构,对于项目A:
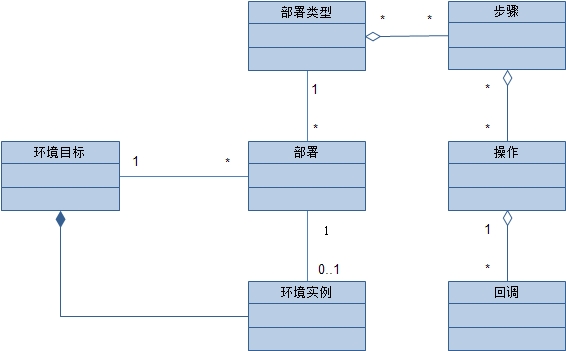
这里,环境依然是处于知识层面(Knowledge Level),它并未与具体的基础设施相关联。当我们将一个环境“具现化”成一个运行系统时,我们就产生了一个真正的环境实例。在这两者之间,我们还必须要考虑环境实例的使用目的(开发?测试?……)以及安装所依赖的其它信息(如机器),因此,我们需要增加一个环境目标来集中这些信息,而且由于不同目标的环境可能会有所差别,因此,环境目标也需要配置的能力。概念模型如图:

图中的环境实例是如何产生的呢?部署,一次部署可能会产生一个环境实例。一系列部署将产生对应于环境目标的多个环境实例,除去当前起作用的环境实例外(最新的),其它的是历史环境实例。通过在历史环境实例中切换,我们自然而然的就可以使整个环境回滚,因为项目所依赖的一切都已经成为的环境中的软件包,而且环境依赖的包的版本会随着部署具体确定下来。如此一来,我们便可以给每个环境实例分配一个版本号,再通过环境实例的版本号与软件包的版本对应起来,从而得知一次部署时应用的具体软件包,如图:
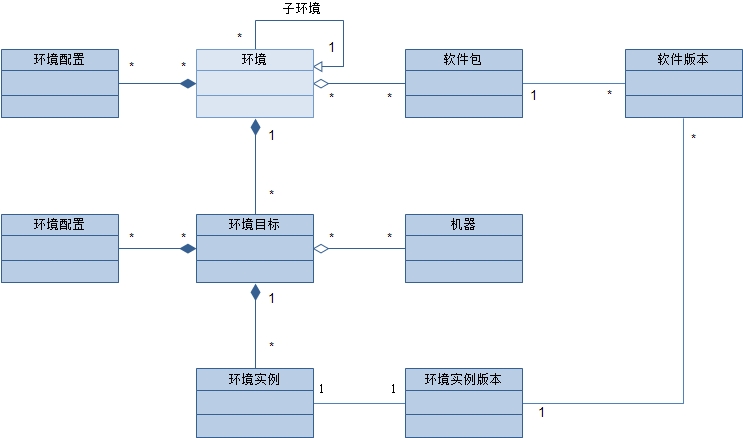
目前的环境管理结构,已经可以解决场景1、2和5的问题。那么对于场景2,运行时依赖,环境管理应该如何解决呢?
细心的朋友,可能已经发现,在环境层面上我们确定了环境依赖的软件包,这里有两个隐藏的含义:
- 环境定义的是对软件包的运行时依赖
- 由于环境是一个逻辑上的概念,因此其所用的软件包也是一个逻辑上的概念(相对于版本控制系统中的软件包)
我们也已经知道,在部署时,一个环境实例将具体的确定其依赖的软件包的版本。某个版本的软件包最终与代码库中的物理的软件包相关联。但软件包是运行时的安装包,因此,它应该是代码库中包编译的结果。在对代码库的包编译时,既要将结果打上版本保存起来,也好在两者的版本间建立关系,最后,编译结果应该是某种既定的安装包目录文件结构。
另外,当环境包含的包比较多时,运行时版本树会非常大,手动的指定全部的包的版本将是一个非常大的体力劳动,这部分工作也要得到简化。由此,我们必须
- 建立逻辑软件包版本和版本库中软件包版本间的关系
- 为相互依赖的包编译并打上统一的标签
- 简化运行时包依赖关系的生产
- 简化运行时包依赖的指定(可参考apt-get和RubyGem,环境只需指定直接依赖的包,间接依赖的包从运行时依赖树中自动导入)
上述讨论还没有涉及操作系统,如果我们的运行机器要支持多个系统,我们又该怎么办???
配置信息也是个大问题,大家可以思考
- 环境配置和应用配置如何区分?
- 如何简化环境配置工作?
- 如何使环境配置的效果只对具体环境有效,而不会泄露到环境外部?
再者,
- 如何使应用支持多运行目标?
- 环境管理如何能方便开发环境的调试?
- 要如何简化版本的选择?
- 在多个包有编译和运行时依赖时,编译时如何检查以减少引入兼容性问题的风险?
这些都留待大家思考。
四、督脉——部署系统
《持续集成》和《持续交付》中都对部署有详细的讨论,不在赘述。在我看来,部署其就是按照其目的执行一系列步骤将环境置于其目的所指向的状态中。我们一会再回国头来看这段文绉绉的话,先看看第一部分持续集成的环境下,我们部署的步骤可能会是下面这个样子:
- 登陆目标机(ssh)
- 停止服务
- 清理环境
- 准备安装环境(创建文件夹等)
- 安装项目包(rsync,解压,权限设置等)
- 配置环境变量
- 启动服务
- ……
而在第二部分的情景4中,我们看到如果对不同的持续集成环境建立不同的部署脚本和环境维护脚本,这部署过程的维护会非常繁琐。基于第三部分的环境管理,我们可以将部署过程抽象为:
现在回到开头那个文绉绉的描述:部署其就是按照其目的执行一系列步骤将环境置于其目的所指向的状态中。
由于我们已经将部署作为环境管理的一部分,而环境又是对外提供服务的最小实体,因此,对环境的部署就是要根据部署的类型,在环境上按一定的步骤执行一系列操作,从而使环境置于部署类型所要的状态,这个过程中可能会生成对应的环境实例。举例来说,我们可能会修改环境相关的一些配置,然后重启环境,显然,这种情况下不需要下载安装软件包(没有改变),因此也就不需要生成环境实例。
对于标准的部署——安装软件包并启动环境,可能的步骤将会是:
- 选择将要部署的软件包的版本
- 生成新的环境实例(确定环境实例的版本和其依赖包的版本,确定环境配置等)
- 清理和准备目标机环境
- 下载包
- 设置环境配置
- 环境实例切换
- 生成部署报告
- ……
好,部署系统和环境管理各就各位,我们可以将各个项目环境纳入我们的环境管理之中,甚至是持续集成环境本身。再补充一句,要让部署系统和环境管理能很好的发挥作用,我们即需要一个简单一致的UI界面(为开发人员),也需要提供一个清晰明了的服务接口(供外部系统调用,如持续部署系统)。对于与环境管理相关的机器状态管理,网络资源的配置等等,本文不再涉及,大家可以自己思考。环境管理的实现、编译系统改造以及持续部署的具体实现,另作文章探讨。
就技术而言(不考虑围绕持续部署的过程实践),环境管理、部署系统以及我们没有提及的编译系统改造才是生产线的真正引擎,持续部署不过是水到渠成的传送带而已。
五、没完
打通了任督二脉后,事还还没有完,还有很多细节上的问题。你想,这个工具实在是太好用了,于是公司里成百上千的工程师们都在使用这个自动化部署系统,我们又会面对很多很多问题:
- 部署系统的性能问题。几百号人不停地在把他们的软件部署到自己的机器上,部署到测试环境,部署到生产环境,一天之内一个人可能会要部署N次,回滚N次,不但有大量部署请求,还有大量的文件在网络上传输。你得想想这套部署系统如何解决这些性能问题,还得考虑未来更大规模的性能水平扩展问题。
- 目标机环境的管理。在目标运行机上需要解决几个问题:1)两个环境间如果有一些的一样的包,那就没有必要再下载了,这样可以节约时间。2)每次部署都需要把老的部署环境给保留下来,这样方便在新旧环境下的切换。这两点对于在生产环境下部署非常关键。(这需要环境内所有软件的绿色安装才能更容易达到这个目标,因些,Unix/Linux会比Windows更容易做到这点)
- 部署一致性事务问题。有时候,我们需要同时部署若干台服务器,比如:包A到机器MA,包B到机器MB,包C到机器MC,……(Web Service的SOA架构),这些包之间有运行依赖性和兼容性问题,要么一次性全部完成,要么就全部失败。回滚也是一样的,这是一个部署事务或部署一致性的问题。如何解决呢?
- 部署环境的版本控制问题。前面说过,我们的一个环境就会和若干个包的版本耦合,环境必需管理要部署的包的版本。于是,当你的部署越来越多的时候,各个环境的包的版本开始出现混乱,各种依赖间的版本也会出现不统一的情况,也就是说,就算你有这样的一个工具,在一个高速开发的环境下,我们的部署环境的管理还是会出现很多混乱的情况,需要你不断地统一大家的开发、测试环境。
- 部署计划。我们可能会有很多部署计划,比如:设定定时部署,提升或降低部署优先级,部署事务定义,部署策略(如:先部署10%的机器,如果没有问题,再把剩下的系统部署了),热切计划和策略…… 等等 ,等等 。
- 部署的监控和维护。任何软件和系统都会有这样的问题,当规模上去了以后,我们的自动化部署系统的监控和维护的复杂度并不亚于一个大型的互联网应用。
六、总结
这里只谈一点自己的看法,从传统的持续集成到面向大型软件的持续部署,我们将系统所依赖的软件环境和软件包抽象为一致的实体纳入到管理之中,并将运维人员的工作真正的分摊到开发人员身上。而云计算的出现,使得计算机本身也可以自动化的创建和回收,这样环境管理的范畴将进一步扩充。相应的,部署的能力和灵活性也是一次质的飞跃,将再一次减轻运维人员的工作压力。
说了这么多废话,总结一下自己的观点,对于向大型软件企业推销基于持续集成的持续部署(交付)的哥们:
- 你就是在耍流氓,如果你不解决环境管理!!!
- 你就是在耍流氓,如果你不建立部署系统!!!
- 你就是在耍流氓,如果你不扩展编译系统!!!
- 你就是在耍流氓,如果你只是推销小团队的实践而不考虑改造大环境!!!
- 你就是个流氓,如果你只是不断地告诉别人怎么做,自己却从来不动手写一个测试或建立一个持续集成环境!!!
最后,用Linus最经典的话来结束本文——“ Talk is Cheap, Show me the Code!”
(注:本文由@常新居士完成初稿,我做了一些编辑,主要写了第五节“没完” )
(转载本站文章请注明作者和出处 酷 壳 – CoolShell ,请勿用于任何商业用途)







 (28 人打了分,平均分: 4.04 )
(28 人打了分,平均分: 4.04 )
《持续部署,并不简单!》的相关评论
赞!好文啊!
板凳
酷~~~~非常经典
好文!这才叫干货!
分享经验才叫真正的分享!
比贴一堆代码的那种强上百倍不止!
后台系统居然都盘根错节到这种程度,会不会是一开始的方向、理念就错了呢?
virtualization 或者 EC2可以很好的解决platform的搭建,Koji 来管理和prompt package能很好的完成持续部署到不同环境, test -> staging -> production
复制走了这篇文章了,放到word中继续读,留给脚印
当你的业务逻辑和目标复杂到一定程度的时候, 实现必然会更加复杂
请问CI服务器是干什么用的?全称是什么?
@芡实
Continuous-Integration-Server
OK,我已经google了,continuous integration Server
@suchasplus
如果考虑到运维系统,部署时机器的状态等,现实的情况比这个更复杂。
一开始用Java方向就错了
@haitao
我们也是这个构架。很接近。所以对于,ci,deploy system,dev,test,stg,prd,这种流程很熟悉。
受益良多,摘录了不少内容,以后慢慢领会!环境管理确实重要,我推荐可以尝试使用puppet+svn(git)来解决
好长,且看不懂。还是写写C代码吧
@牛角博客
这年头了还这么麻烦呀,推荐wiz或者印象笔记(evernote)
世界上的事情往往如此。小规模的时候,一切都不是问题。当规模增长的时候,很多原本微不足道的事情都成了大问题。
好文
非常赞同“ Talk is Cheap, Show me the Code!”这句话啊!!!
持续部署非常复杂,尤其对于大的项目而言。一些所谓的咨询师,可能也就做过一些一两百万行代码的项目。他们就会动动嘴。
耐着性子看完了,虽然不太懂
Hi 陈皓,
首先感谢精彩的内容及分享,我看了这篇马上想到之前看到的一篇文章,贴在这里,或许对大家有实践的帮助。
首先,用别人的一段话作为简介,内容和链接在后
“Etsy has been boasting the number of “deploys” to production per day for a while now — no surprise, given the supervision of one John Allspaw of DevOps Fame. I’ve seen people ask why they should be impressed by, say, 30 deployments per day, and whether or not this constant state of flux might not imply a certain instability, but that is missing the point. Pushing code or changes into production several times a day is not really all that exciting when you only focus on what changes might be made. What is exciting is having the ability to do so.”
//////////////
the link is here:
http://codeascraft.etsy.com/2012/03/13/making-it-virtually-easy-to-deploy-on-day-one/
////////////////////////////////////
Making it Virtually Easy to Deploy on Day One
Posted by John Goulah | Filed under engineering, infrastructure
At Etsy we have one hard and fast rule for new Engineers on their first day: deploy to production. We’ve talked a lot in the past about our deployment, metrics, and testing processes. But how does the development environment facilitate someone coming in on day one and contributing something that takes them through the steps of committing code, running it through our tests, and deploying it with deployinator?
A new engineer’s first task is to snap a photo using our in house photo booth (handmade of course) and upload it to the about page. Everyone gets a shiny new virtual machine with a working development version of the site, along with their LDAP credentials, github write access, and laptop. We use an internal cloud system for the VM’s, mostly because it was the most fun thing to build, but also gives us the advantage of our fast internal network and dedicated hardware. The goal is a consistent environment that mirrors production as closely as possible. So what is the simplest way to build something like this in house?
We went with a KVM/QEMU based solution which allows for native virtualization. As an example of how you may go about building an internal cloud, here’s a little bit about our hardware setup. The hypervisor runs on HP DL380 G7 servers that provide us with a total 72G RAM and 24 cores per machine. We provision 11 guests per server, which allows each VM 2 CPU cores, 5G RAM, and a 40G hard drive. Libvirt supports live migrations across non-shared storage (in QEMU 0.12.2+) with zero downtime which makes it easy to allocate and balance VM’s across hosts if adjustments need to be made throughout the pool.
We create CentOS based VM’s from a disk template that is maintained via Openstack Glance, which is a tool that provides services for discovering, registering, and retrieving virtual images. The most recent version of the disk images are kept in sync via glance, and exist locally on each server for use in the creation of a new VM. This is faster than trying to pull the image over the network on creation or building it from scratch using Kickstart like we do in production. The image itself may have been kickstarted to match our production baseline, and we template a few key files such as the network and hosts information which is substituted on creation, but in the end the template is just a disk image file that we copy and reuse.
The VM creation process involves pushing a button on an internal web page that executes a series of steps. Similar to our one button deployment system, this allows us to iterate on the underlying system without disruption to the overall process. The web form only requires a username which must be valid in LDAP so that the user can later login. From there the process is logged such that it that provides realtime feedback to the browser via websockets. The first thing that happens is we find a valid IP in the subnet range, and we use nsupdate to add the DNS information about the VM. We then make a copy of the disk template which serves as the new VM image and use virt-install to provision the new machine. Knife bootstrap is then kicked off which does the rest of the VM initialization using chef. Chef is responsible for getting the machine in a working state, configuring it so that it is running the same version of libraries and services as the other VM’s, and getting a checkout of the running website.
Chef is a really important part of managing all of the systems at Etsy, and we use chef environments to maintain similar cookbooks between development and production. It is extremely important that development does not drift from production in its configuration. It also makes it much easier to roll out new module dependencies or software version updates. The environment automatically stays in sync with the code and is a prime way to avoid strange bugs when moving changes from development to production. It allows for a good balance between us keeping things centralized, controlled, and in a known-state in addition to giving the developers flexibility over what they need to do.
At this point the virtual machine is functional, and the website on it can be loaded using the DNS hostname we just created. Our various tools can immediately be run from the new VM, such as the try server, which is a cluster of around 60 LXC based instances that spawn tests in parallel on your upcoming patch. Given this ability to modify and test the code easily, the only thing left is to overcome any fear of deployment by hopping in line and releasing those changes to the world. Engineers can be productive from day one due to our ability to quickly create a consistent environment to write code in.
初学呀….几时我才能看懂
@niko
请参看好文的最后一句,哈哈
@aochant
@niko回复错了,不好意思
@aochant 请参看好文的最后一句,哈哈
博主的图画的真不错,请问是用什么工具?
@Yongmin
OS 级别的virtualization解决持续集成有点资源浪费了, 但是不virtualization的话, 资源竞争比如端口号占用什么的又不好解决。 我记得solaris有个zone的概念,如果zone这类的概念能解决掉资源问题, 而且不用OS级别虚拟化, 我觉得在云端上搞这些挺好的。 公司里目前就在推云上搞定CI,前期效果还不错。 但是规模还小。 大部分还没上云。
看完这么多文字,头很晕。
老大是不是你们的系统少了个叫自动升级的模块?
请问您的图是用什么工具画的?谢谢!
我觉得最恶心的不是A依赖于python2而B依赖于python3这个问题,而是python安装的时候非要XX的装进global配置,就不肯给一个绿色的box环境。我觉得作为一个library,根本不应该替用户决定他要如何安装和被识别的问题,应该总是由使用library的人来做。不过话说回来,如果是.net,一个包依赖于2.0,另一个包依赖于4.0,尽管runtime不一样,但是那是完全没有关系的。只有向下兼容的lib才可以做进global配置。
@vczh
python的全局配置和库确实是个问题。即使用virtualenv也不能解决(你不可能在一个操作系统上装两个版本的python及其运行环境),相比来说,ruby这方面做的比较好。他每个版本都是自治的,所以可以多个版本共存,并且任意切换。
OS级别的virtualization用在持续集成里面还是很有必要的吧。virtualization制作和维护自动化脚本的成本不高, 完全可以和genkens集成。 其次物理资源的占用也不算高,一个server完全可以模拟一个4~6个虚拟机的cluster, 完全适合DEV,TST, stage 这些级别的自动编译和部署。
Continus Integration持续集成@芡实
@平阳
求指导 >-< 我虽然搭建了 git , ci,deploy system,dev,test,stage, production, UAT 系统而且也在用,但毕竟没进过公司,不知道正规的开发是怎么样的,能分享一下贵司开发、测试、部署的流程么? (T_T )
开发环境虚拟化是否可以解决一部分问题呢。
这个部署系统也是个大项目啊,不亚于大型互联网项目。
您的图是用什么工具画的?
敏捷适合小团队
您好,很不错的文章。
您好,我们公司使用hudson做每日构建:编译、代码检查(checkstyle、findbugs)、反馈;现加入自动化部署,但自动化数据库集成遇到了问题。开发和测试各有一套数据库,自动化数据库使用他们的数据库,还是单独一套数据库?
现在有了 Docker,持续部署的工作量会减轻不少,作者可以针对 Docker 更新一下这篇文章
初学者2021年看到这篇文章,才感受到docker的了不起,虽然docker已经要被干掉了…
@米糯牛
请教你一下,您们现在有在基于Docker做持续部署吗?分享分享经验吧!3Q
读老文才发现自己跟大牛的差距至少还有4年
“功能在部署到生产环境前要先部署的一个测试环境”貌似有错别字,应该是“功能在部署到生产环境前要先部署到一个测试环境”
耗叔10年前的文章都这么牛逼。。。