Go 编程模式:错误处理
 错误处理一直以一是编程必需要面对的问题,错误处理如果做的好的话,代码的稳定性会很好。不同的语言有不同的出现处理的方式。Go语言也一样,在本篇文章中,我们来讨论一下Go语言的出错出处,尤其是那令人抓狂的
错误处理一直以一是编程必需要面对的问题,错误处理如果做的好的话,代码的稳定性会很好。不同的语言有不同的出现处理的方式。Go语言也一样,在本篇文章中,我们来讨论一下Go语言的出错出处,尤其是那令人抓狂的 if err != nil 。
在正式讨论Go代码里满屏的 if err != nil 怎么办这个事之前,我想先说一说编程中的错误处理。这样可以让大家在更高的层面理解编程中的错误处理。
本文是全系列中第2 / 10篇:Go编程模式
C语言的错误检查
首先,我们知道,处理错误最直接的方式是通过错误码,这也是传统的方式,在过程式语言中通常都是用这样的方式处理错误的。比如 C 语言,基本上来说,其通过函数的返回值标识是否有错,然后通过全局的 errno 变量并配合一个 errstr 的数组来告诉你为什么出错。
为什么是这样的设计?道理很简单,除了可以共用一些错误,更重要的是这其实是一种妥协。比如:read(), write(), open() 这些函数的返回值其实是返回有业务逻辑的值。也就是说,这些函数的返回值有两种语义,一种是成功的值,比如 open() 返回的文件句柄指针 FILE* ,或是错误 NULL。这样会导致调用者并不知道是什么原因出错了,需要去检查 errno 来获得出错的原因,从而可以正确地处理错误。
一般而言,这样的错误处理方式在大多数情况下是没什么问题的。但是也有例外的情况,我们来看一下下面这个 C 语言的函数:

 (44 人打了分,平均分: 4.09 )
(44 人打了分,平均分: 4.09 )
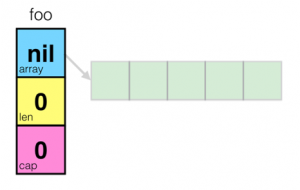 熟悉C/C++的同学一定会知道,在结构体里用数组指针的问题——数据会发生共享!下面我们来看一下slice的一些操作
熟悉C/C++的同学一定会知道,在结构体里用数组指针的问题——数据会发生共享!下面我们来看一下slice的一些操作 (50 人打了分,平均分: 4.30 )
(50 人打了分,平均分: 4.30 ) 本文来自读者“程序猿石头”的投稿文章《
本文来自读者“程序猿石头”的投稿文章《 好久没有写一些微观方面的文章了,今天写一篇关于CPU Cache相关的文章,这篇文章比较长,主要分成这么几个部分:基础知识、缓存的命中、缓存的一致性、相关的代码示例和延伸阅读。其中会讲述一些多核 CPU 的系统架构以及其原理,包括对程序性能上的影响,以及在进行并发编程的时候需要注意到的一些问题。这篇文章我会尽量地写简单和通俗易懂一些,主要是讲清楚相关的原理和问题,而对于一些细节和延伸阅读我会在文章最后会给出相关的资源。
好久没有写一些微观方面的文章了,今天写一篇关于CPU Cache相关的文章,这篇文章比较长,主要分成这么几个部分:基础知识、缓存的命中、缓存的一致性、相关的代码示例和延伸阅读。其中会讲述一些多核 CPU 的系统架构以及其原理,包括对程序性能上的影响,以及在进行并发编程的时候需要注意到的一些问题。这篇文章我会尽量地写简单和通俗易懂一些,主要是讲清楚相关的原理和问题,而对于一些细节和延伸阅读我会在文章最后会给出相关的资源。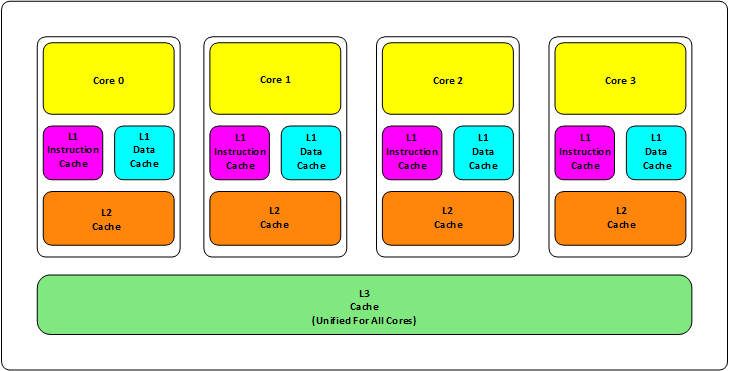
 HTTP (Hypertext transfer protocol) 翻译成中文是超文本传输协议,是互联网上重要的一个协议,由欧洲核子研究委员会CERN的英国工程师
HTTP (Hypertext transfer protocol) 翻译成中文是超文本传输协议,是互联网上重要的一个协议,由欧洲核子研究委员会CERN的英国工程师  我们知道,HTTP是无状态的,所以,当我们需要获得用户是否在登录的状态时,我们需要检查用户的登录状态,一般来说,用户的登录成功后,服务器会发一个登录凭证(又被叫作Token),就像你去访问某个公司,在前台被认证过合法后,这个公司的前台会给你的一个访客卡一样,之后,你在这个公司内去到哪都用这个访客卡来开门,而不再校验你是哪一个人。在计算机的世界里,这个登录凭证的相关数据会放在两种地方,一个地方在用户端,以Cookie的方式(一般不会放在浏览器的Local Storage,因为这很容易出现登录凭证被XSS攻击),另一个地方是放在服务器端,又叫Session的方式(SessonID存于Cookie)。
我们知道,HTTP是无状态的,所以,当我们需要获得用户是否在登录的状态时,我们需要检查用户的登录状态,一般来说,用户的登录成功后,服务器会发一个登录凭证(又被叫作Token),就像你去访问某个公司,在前台被认证过合法后,这个公司的前台会给你的一个访客卡一样,之后,你在这个公司内去到哪都用这个访客卡来开门,而不再校验你是哪一个人。在计算机的世界里,这个登录凭证的相关数据会放在两种地方,一个地方在用户端,以Cookie的方式(一般不会放在浏览器的Local Storage,因为这很容易出现登录凭证被XSS攻击),另一个地方是放在服务器端,又叫Session的方式(SessonID存于Cookie)。
 要说清 Systemd,得先从Linux操作系统的启动说起。Linux 操作系统的启动首先从 BIOS 开始,然后由 Boot Loader 载入内核,并初始化内核。内核初始化的最后一步就是启动 init 进程。这个进程是系统的第一个进程,PID 为 1,又叫超级进程,也叫根进程。它负责产生其他所有用户进程。所有的进程都会被挂在这个进程下,如果这个进程退出了,那么所有的进程都被 kill 。如果一个子进程的父进程退了,那么这个子进程会被挂到 PID 1 下面。(注:PID 0 是内核的一部分,主要用于内进换页,参看:
要说清 Systemd,得先从Linux操作系统的启动说起。Linux 操作系统的启动首先从 BIOS 开始,然后由 Boot Loader 载入内核,并初始化内核。内核初始化的最后一步就是启动 init 进程。这个进程是系统的第一个进程,PID 为 1,又叫超级进程,也叫根进程。它负责产生其他所有用户进程。所有的进程都会被挂在这个进程下,如果这个进程退出了,那么所有的进程都被 kill 。如果一个子进程的父进程退了,那么这个子进程会被挂到 PID 1 下面。(注:PID 0 是内核的一部分,主要用于内进换页,参看: 之前写过一篇《
之前写过一篇《