7个示例科普CPU Cache
(感谢网友 @我的上铺叫路遥 翻译投稿)
CPU cache一直是理解计算机体系架构的重要知识点,也是并发编程设计中的技术难点,而且相关参考资料如同过江之鲫,浩瀚繁星,阅之如临深渊,味同嚼蜡,三言两语难以入门。正好网上有人推荐了微软大牛Igor Ostrovsky一篇博文《漫游处理器缓存效应》,文章不仅仅用7个最简单的源码示例就将CPU cache的原理娓娓道来,还附加图表量化分析做数学上的佐证,个人感觉这种案例教学的切入方式绝对是俺的菜,故而忍不住贸然译之,以飨列位看官。
原文地址:Gallery of Processor Cache Effects
大多数读者都知道cache是一种快速小型的内存,用以存储最近访问内存位置。这种描述合理而准确,但是更多地了解一些处理器缓存工作中的“烦人”细节对于理解程序运行性能有很大帮助。
在这篇博客中,我将运用代码示例来详解cache工作的方方面面,以及对现实世界中程序运行产生的影响。
下面的例子都是用C#写的,但语言的选择同程序运行状况以及得出的结论几乎没什么影响。
示例1:内存访问和运行
你认为相较于循环1,循环2会运行多快?
int[] arr = new int[64 * 1024 * 1024]; // Loop 1 for (int i = 0; i < arr.Length; i++) arr[i] *= 3; // Loop 2 for (int i = 0; i < arr.Length; i += 16) arr[i] *= 3;

 (55 人打了分,平均分: 4.00 )
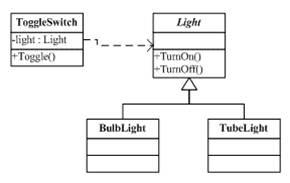
(55 人打了分,平均分: 4.00 ) 关于IoC的的概念提出来已经很多年了,其被用于一种面象对像的设计。我在这里再简单的回顾一下这个概念。我先谈技术,再说管理。
关于IoC的的概念提出来已经很多年了,其被用于一种面象对像的设计。我在这里再简单的回顾一下这个概念。我先谈技术,再说管理。

 一两个月前在淘宝内网里看到一个优化Javascript代码的竞赛,发现有不少的人对Javascript的执行和装载的基础并不懂,所以,从那天起我就想写一篇文章,但一直耽搁了。自上篇《
一两个月前在淘宝内网里看到一个优化Javascript代码的竞赛,发现有不少的人对Javascript的执行和装载的基础并不懂,所以,从那天起我就想写一篇文章,但一直耽搁了。自上篇《
 在淘宝内网里看到同事发了贴说了一个CPU被100%的线上故障,并且这个事发生了很多次,原因是在Java语言在并发情况下使用HashMap造成Race Condition,从而导致死循环。这个事情我4、5年前也经历过,本来觉得没什么好写的,因为Java的HashMap是非线程安全的,所以在并发下必然出现问题。但是,我发现近几年,很多人都经历过这个事(在网上查“HashMap Infinite Loop”可以看到很多人都在说这个事)所以,觉得这个是个普遍问题,需要写篇疫苗文章说一下这个事,并且给大家看看一个完美的“Race Condition”是怎么形成的。
在淘宝内网里看到同事发了贴说了一个CPU被100%的线上故障,并且这个事发生了很多次,原因是在Java语言在并发情况下使用HashMap造成Race Condition,从而导致死循环。这个事情我4、5年前也经历过,本来觉得没什么好写的,因为Java的HashMap是非线程安全的,所以在并发下必然出现问题。但是,我发现近几年,很多人都经历过这个事(在网上查“HashMap Infinite Loop”可以看到很多人都在说这个事)所以,觉得这个是个普遍问题,需要写篇疫苗文章说一下这个事,并且给大家看看一个完美的“Race Condition”是怎么形成的。